[인공지능 수학] 확률분포 총정리 및 PCA 주성분분석 기초 (feat. Pandas/Numpy/SageMath 실습)
📌 오늘의 학습 목표
데이터 분석과 인공지능 모델링에서 “이 데이터가 어떤 모양(분포)을 띠고 있는가?”를 파악하는 것은 모델의 성능을 좌우하는 핵심임. 이번 포스트에서는 다양한 확률분포의 종류를 일상생활의 비유로 정복하고, 데이터 축소의 끝판왕인 PCA까지 알아봄!
- 이산확률분포: 딱딱 떨어지는 결과(성공/실패)를 다루는 베르누이 분포, 이항 분포, 포아송 분포를 실습함.
- 연속확률분포: 키나 시간처럼 이어지는 결과를 다루는 균등 분포, 정규 분포, 지수 분포를 실습함.
- 결합확률 & 공분산: 두 개 이상의 변수가 서로 어떻게 얽혀서 영향을 주는지(상관계수) 파악함.
- 주성분 분석 (PCA): 쓸데없는 데이터를 쳐내고 핵심 엑기스(차원)만 남기는 과정을 정리함.
1. 이산확률분포: 결과가 딱딱 떨어지는 세계
🎲 [예제 1] 베르누이 분포 (Bernoulli Distribution)
결과가 오직 “성공(1)” 아니면 “실패(0)” 두 가지뿐인 모 아니면 도의 세계임. 동전 던지기(앞/뒷면), 스팸 메일 판별(스팸/정상)처럼 인공지능 이진 분류(Binary Classification)의 가장 밑바탕이 됨.
import numpy as np
from scipy.stats import bernoulli
# 성공(앞면)이 나올 확률이 30%(0.3)인 찌그러진 동전 세팅
p = 0.3
# 베르누이 시행을 10번 던져봄 (1: 성공, 0: 실패)
trials = bernoulli.rvs(p, size=10)
print("--- 베르누이 시행 10번 결과 ---")
print(trials) # 예: [0 0 1 0 1 0 0 0 1 0]
🎲 [예제 - 추가] 이항 분포와 포아송 분포, 그리고 포아송 근사
- 이항 분포(Binomial): 베르누이 시행(동전 던지기)을 $N$번 무한 반복했을 때, 성공 횟수 $X$가 그리는 종 모양의 분포임.
- 포아송 분포(Poisson): “1시간 동안 우리 매장에 손님이 몇 명이나 올까?”처럼, 특정 시간/공간 내에서 아주 드물게(희귀하게) 발생하는 사건의 횟수를 예측할 때 씀.
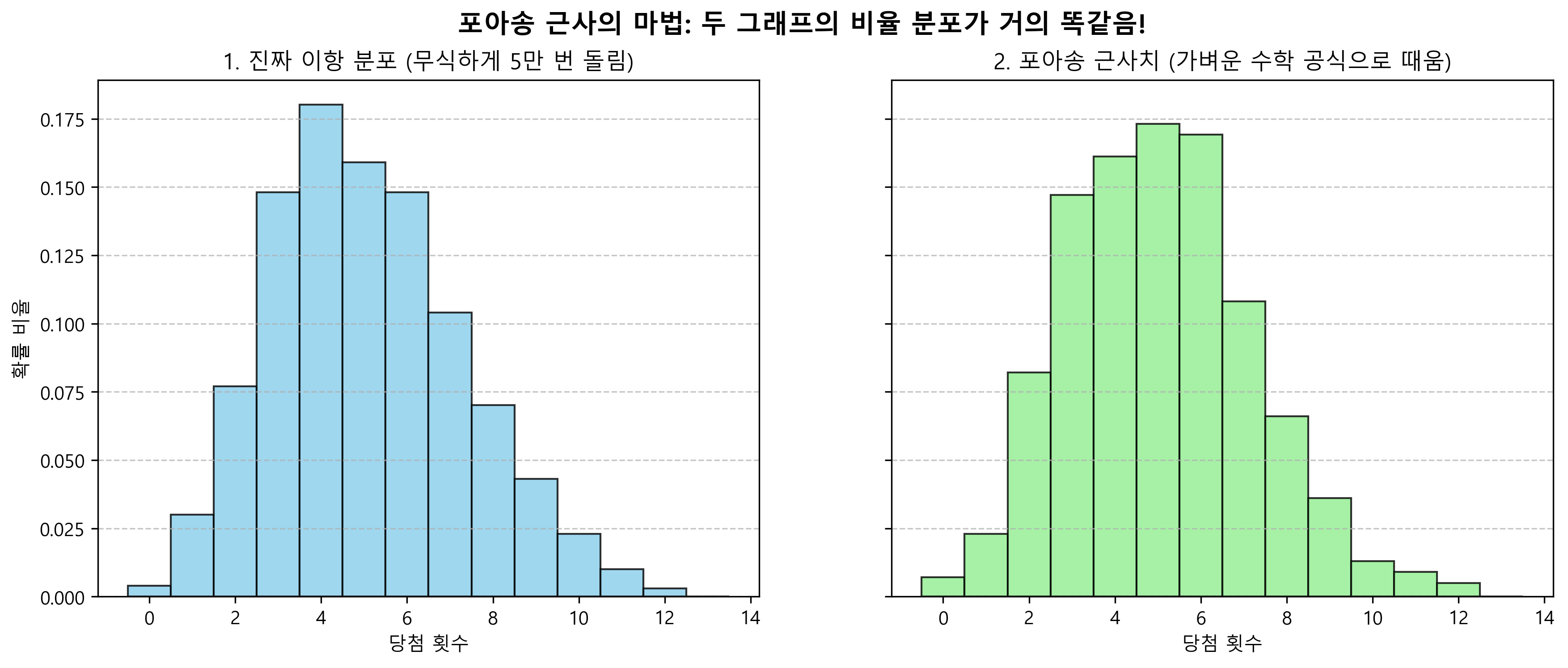
💡 포아송 근사 (Poisson Approximation) 동전을 50,000번 엄청나게 많이 던지는데($N \to \infty$), 하필 성공할 확률이 로또 당첨처럼 극도로 낮다면($P \to 0$)? 이때 복잡한 이항 분포 계산을 집어치우고, 포아송 분포 수식으로 퉁쳐서 계산(근사)해도 결과가 거의 똑같다는 마법의 정리임!
import numpy as np
# N(시도 횟수) = 5만 번 / P(성공 확률) = 0.0001 (매우 희박)
N = 50000
P = 0.0001
# 1. 원본: 이항 분포로 시뮬레이션 돌리기!
# np.random.binomial(n, p, 시도횟수)
binom_results = np.random.binomial(N, P, size=1000)
# 2. 짭(근사): 포아송 분포로 시뮬레이션 돌리기!
# 포아송의 기댓값 람다(lam) = N * P = 5
lam = N * P
poisson_results = np.random.poisson(lam, size=1000)
print(f"이항분포 평균 당첨 횟수: {binom_results.mean():.2f}번")
print(f"포아송분포 평균 당첨 횟수: {poisson_results.mean():.2f}번")
# 두 결과가 প্রায় "5번"으로 소름 돋게 일치함! 이것이 포아송 근사의 위력.
(아래 히스토그램을 보면, 왼쪽의 5만 번 생고생해서 돌린 이항 분포 결과나 오른쪽의 포아송 공식으로 퉁친 결과나 확률 분포 모양이 완전히 쌍둥이처럼 똑같은 것을 볼 수 있음!)
2. 연속확률분포: 값이 무한히 쪼개지는 세계
📏 [예제 6] 균등 분포 (Uniform Distribution)
버스를 기다리는데 배차 간격 10분 내에 “어느 타이밍에 도착하든 확률이 완전히 똑같이 공평한” 상태임. 그래프를 그리면 네모 반듯한 직사각형 지붕 모양이 됨. (모든 구간 확률이 동일함)
import numpy as np
# 0분에서 10분 사이에 버스가 올 확률이 완벽히 똑같은(공평한) 균등분포!
# 5개의 도착 시간 난수를 뽑아봄
bus_arrivals = np.random.uniform(low=0, high=10, size=5)
print("--- 균등분포 기반 예상 버스 도착 시간(분) ---")
print(np.round(bus_arrivals, 2))
📏 [예제 7] 표준 정규 분포 (Standard Normal Distribution)
키, 몸무게, 시험 점수 등 세상 만물의 90%가 따르는 가장 위대한 종 모양(Bell-curve) 그래프임. 그중에서도 통계학을 편하게 하려고 평균을 영(0)으로 멱살 잡고 끌어내리고, 흩어진 정도(표준편차)를 1로 깔끔하게 규격화시킨 것을 표준 정규 분포라고 부름.
import numpy as np
# 표준 정규 분포 (평균 0, 표준편차 1)에서 데이터 10개 추출
# randn의 n은 Normal(정규)를 의미함
std_normals = np.random.randn(10)
print("--- 표준 정규분포 데이터 추출 (0을 중심으로 모여있음) ---")
print(np.round(std_normals, 2))
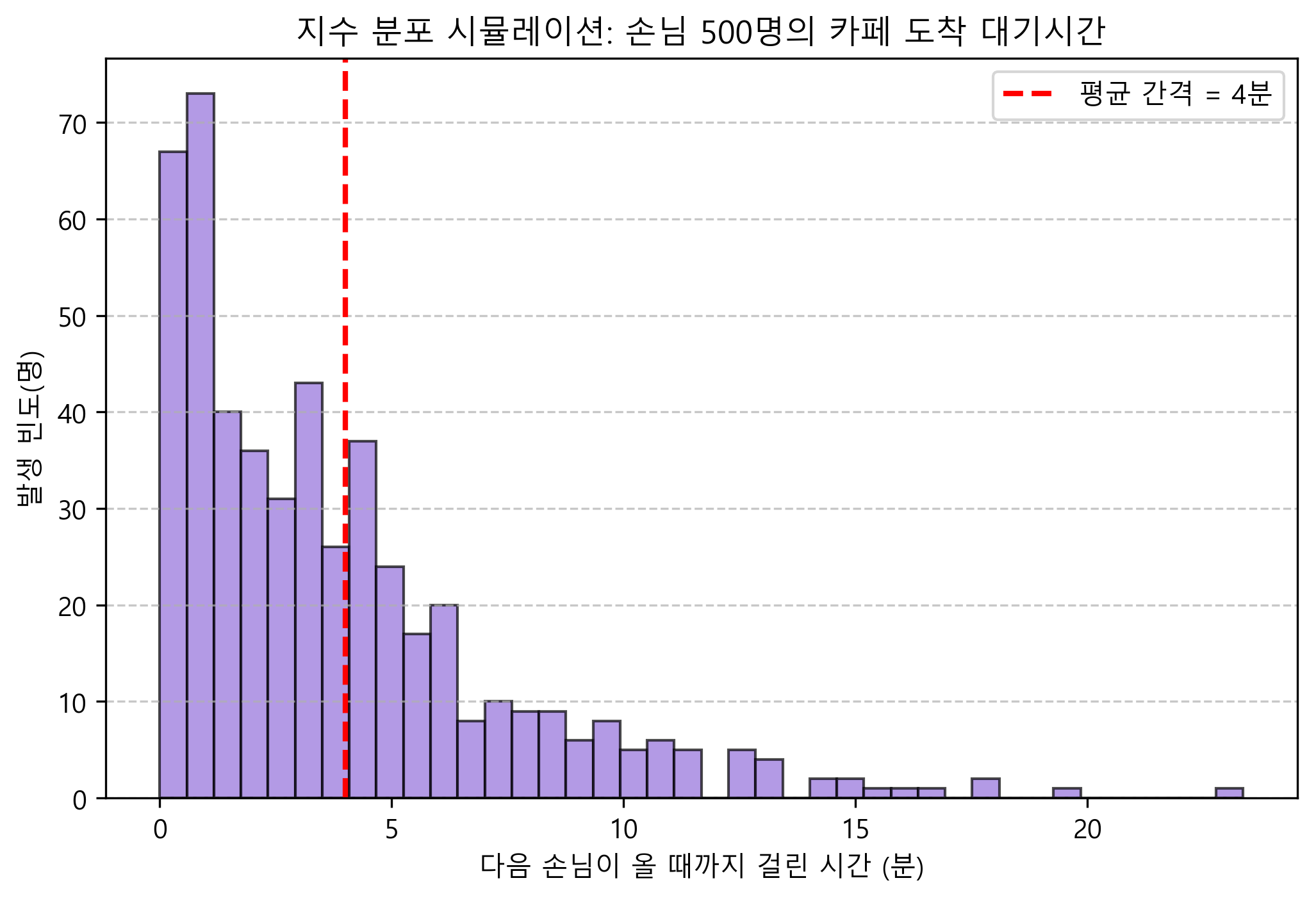
☕ [지수 분포 시뮬레이션] 카페 대기 시간의 비밀
- 지수 분포(Exponential): 버스나 손님이 “다음 번에 도착할 때까지 걸리는 대기 시간” 을 나타내는 분포임. 포아송 분포가 ‘횟수’라면, 지수 분포는 사건과 사건 사이의 ‘시간 간격’임!
import pandas as pd
import numpy as np
# 카페의 평균 고객 도착 시간 = 4분 (1명 오는데 4분 걸림)
mean_arrival_time = 4
# 지수분포 공식을 따르는 난수(도착 간격) 500개를 생성함!
# scale 파라미터에 평균 대기시간(4)을 넣어줌.
# exponential()은 왼쪽으로 쏠린 미끄럼틀 모양의 분포를 만듦. (빨리 오는 손님이 대다수!)
intervals = np.random.exponential(scale=mean_arrival_time, size=500)
df_cafe = pd.DataFrame({'Customer_ID': range(1, 501), 'Arrival_Interval(m)': intervals})
print("--- 하루 500명 카페 손님의 도착 간격 시간(첫 5명) ---")
print(df_cafe.head().round(2))
print(f"\n검증: 500명 평균 도착 간격 = {df_cafe['Arrival_Interval(m)'].mean():.2f}분 (목표 4분과 일치!)")
(아래 시뮬레이션 그래프를 보면 대기시간 0~2분 사이에 손님들이 폭발적으로 몰려있고(왼쪽 쏠림), 10~20분 넘게 안 오는 경우는 드물게 꼬리처럼 길게 늘어지는 것을 확인할 수 있음!)
3. 다변량 데이터: 변수들이 얽히고설킨 관계
🔗 [예제 15] 결합 확률 밀도 함수 (Joint PDF)
몸무게(X) 곡선 지붕 하나, 키(Y) 곡선 지붕 하나를 따로 볼 게 아니라, 두 조건을 동시에 고려했을 때 확률이 어떻게 되는지 X, Y, Z라는 3차원 산봉우리 모양으로 확률의 부피를 구하는 개념임.
단일 확률밀도함수가 2차원 곡선의 ‘넓이(적분 1회)’를 구했다면, 결합 확률 밀도 함수는 3차원 산봉우리의 ‘부피(이중 적분 2회)’를 구해 확률을 알아냄.
# SageMath 환경에서 실행
x, y = var('x, y')
# 3차원 산봉우리 모양의 결합확률밀도함수 설정 f(x, y) = x + y
f(x, y) = x + y
# X가 0부터 1까지, Y가 0부터 1까지 변할 때 전체 확률(부피) 구하기
# 적분을 두 번 연속으로 함 (이중 적분!)
total_probability_volume = integrate(integrate(f(x, y), x, 0, 1), y, 0, 1)
print(f"X와 Y를 동시에 고려한 해당 구간의 전체 확률 부피: {total_probability_volume}")
# 결과가 1이 나온다면? (100%), 즉 완벽한 확률 덩어리라는 의미임!
🔗 [예제 16] 공분산 (Covariance), 상관계수, 공분산 행렬
키가 크면 몸무게도 무거워질까? 두 데이터 항목이 서로 짝짜꿍이 맞아서 같이 움직이는지, 반대로 철천지원수처럼 엇갈려 움직이는지 측정하는 지표임.
- 공분산 (Covariance, $Cov$): 양수면 정비례, 음수면 반비례임. 근데 숫자 단위가 지멋대로라 “이게 얼마나 강하게 연관된 건지” 측정하기 어려움.
- 상관계수 (Correlation, $R$): 공분산의 지멋대로 몸집을
-1부터1사이의 깔끔한 숫자로 압축(정규화)한 것. 1에 가까울수록 피의 결맹 수준으로 같이 움직이는 거임! - 공분산 행렬 (Covariance Matrix): 피처(Feature)가 수십 개일 때, 얘네들끼리 1:1로 짝지어 공분산 값을 엑셀 표(행렬)로 정리해 둔 요약본. 대칭행렬의 꽃임.
import numpy as np
# x = 공부한 시간 / y = 시험 점수
# 공부 시간이 늘어날수록 점수도 오르는 강력한 양의 상관관계 데이터!
x = np.array([2, 4, 6, 8, 10])
y = np.array([40, 60, 75, 85, 95])
# 공분산 행렬 (Covariance Matrix) 구하기
# 원소를 보면 대각선은 자기 자신분산, 모서리는 X와 Y의 공분산임.
cov_matrix = np.cov(x, y)
print("--- 공분산 행렬 ---")
print(cov_matrix)
print(f"X와 Y의 공분산(양수): {cov_matrix[0, 1]:.2f}")
# 상관계수 행렬 구하기 (Correlation Coefficient)
corr_coeff = np.corrcoef(x, y)[0, 1]
print(f"X와 Y의 상관계수 (최대 1): {corr_coeff:.4f} (거의 1! 엄청난 정비례!)")
4. PCA (주성분 분석, Principal Component Analysis) 실행 과정 이해
AI 모델에 집값 데이터를 넣으려 함. 방 갯수, 화장실 갯수, 집 크기 등 데이터 종류(차원)가 1,000개나 됨. 이렇게 폭발적으로 많은 변수는 컴퓨터를 헷갈리게 하고 버벅이게 만듦.
이때 “잔가지(스레기 데이터)는 다 쳐내고, 데이터를 가장 잘 설명하는 핵심 뼈대 두세 개만 남기자!” 하는 마법의 정보 압축 기술이 바로 PCA 주성분분석임. 이 과정은 방금 배운 ‘공분산 행렬’을 베이스로 굴러감!
⚙️ PCA 알고리즘의 실행 프로세스 4스텝
- 데이터 정규화 (Standardization): 변수들끼리의 단위(예: ‘개수’와 ‘면적’)가 달라서 왜곡되는 걸 막기 위해, 전부 평균 0, 표준편차 1로 스케일을 맞춰 통일시킴.
- 공분산 행렬 도출 (Covariance Matrix): 위에서 배운 대로 데이터들끼리 서로 어떻게 얽혀 노는지 상관관계를 나타내는 대칭 표(행렬)를 생성함.
- 고유값과 고유벡터 추출 (Eigenvalues & Eigenvectors): 공분산 행렬에서 마법의 수학을 써서 “데이터가 가장 심하게 분산된 메인 축(방향 = 고유벡터)”과 “그 축의 중요도 크기(고유값)”를 뽑아냄. (이 축이 바로 주성분(Principal Component, PC)임!)
- 차원 축소 (Projection): 1,000개 축 중에서 중요도(고유값)가 제일 큰 1등 축(PC1)과 2등 축(PC2) 딱 2개만 남기고 나머진 버림. 그리고 원본 데이터들을 이 두 핵심 축 스크린에 그림자(정사영/Projection)로 비추어 저장하면, 정보 손실은 최소화하면서 용량은 확 줄인 “2차원 압축 데이터”가 완성됨!
Comments