[인공지능 수학] 확률, 순열/조합, 베이즈 정리부터 분산까지 (feat. Pandas/Numpy 실습)
📌 오늘의 학습 목표
인공지능, 특히 머신러닝(Machine Learning) 모델은 기본적으로 “이 데이터가 정답일 확률이 얼마나 될까?”를 끝없이 추론하는 통계적 기계임. 따라서 확률과 통계를 모르면 모델의 성능을 제대로 평가할 수 없음.
- 순열과 조합: 순서가 중요한 줄 세우기와 순서 없는 팀 짜기의 차이를 [예제 1, 2]로 실습함.
- 조건부 확률 (시뮬레이션): 동전과 주사위를 10만 번 던져보는 무식하지만 확실한 코드로 확률을 체감해 봄.
- 확률밀도함수 (PDF): 연속적인 데이터에서 “확률”을 어떻게 구하는지 [예제 2]로 이해함.
- 베이즈 정리 (Bayes’ Theorem): “결과를 보고 원인을 역추적”하는 인공지능 추론의 핵심 마법을 [예제 4]로 배움.
- 기댓값, 분산, 표준편차: 데이터가 기댓값(평균)으로부터 얼마나 들쭉날쭉하게 흩어져 있는지 수치화하는 방법을 [예제 1]로 알아봄.
- 파이썬 실습:
SageMath,Pandas,Numpy패키지 3대장을 총동원해서 파이썬 코드로 자동화해 봄.
1. 경우의 수 세기의 기초: 순열(Permutation)과 조합(Combination)
가장 기초적인 확률을 구하려면 일단 “전체 일어날 수 있는 가짓수(경우의 수)”를 셀 줄 알아야 함. 이때 무조건 기억해야 할 두 가지 마법의 단어가 있음.
- 순열 (Permutation, $P$): “야, 너희들 달리기 시합해서 1등, 2등, 3등 순서대로 줄 서!”
- 순서가 굉장히 중요함. (A가 1등, B가 2등인 것과 / B가 1등, A가 2등인 것은 완전 다른 경우로 취급함)
- 조합 (Combination, $C$): “순서 상관없이 우리 반에서 청소 당번 3명만 대충 뽑자!”
- 순서가 전혀 안 중요함. (A, B, C가 뽑히나 / C, A, B가 뽑히나 결국 같은 청소팀 하나로 퉁침)
따라서 항상 “순열 결과 치수 > 조합 결과 치수” 일 수밖에 없음. 조합은 중복되는 순서를 하나로 뭉개버리기 때문임.
🧮 순열과 조합 코드 실습 (in SageMath & Python)
# SageMath/Python 환경에서 실행
import math
# [예제 1: 순열] 5명의 학생 중 반장, 부반장을 차례대로 뽑는 경우의 수
# 5명 중 2명을 '순서대로' 줄 세우기 (5_P_2)
n = 5
r = 2
# 퍼뮤테이션 수식: 5! / (5-2)! = 5 * 4 = 20
num_permutations = math.factorial(n) // math.factorial(n - r)
print(f"5명 중 2명을 반장/부반장으로 뽑는 순열(P) 경우의 수: {num_permutations}가지")
# [예제 2: 조합] 5명의 학생 중 청소 당번 2명을 순서 없이 뽑는 경우의 수
# 5명 중 2명을 '대충' 뽑기 (5_C_2)
# 콤비네이션 수식: 5! / (2! * (5-2)!) = 20 / 2 = 10
num_combinations = math.comb(n, r)
print(f"5명 중 2명을 청소 당번으로 뭉뚱그려 뽑는 조합(C) 경우의 수: {num_combinations}가지")
💡 결과 직관적 이해
- 순열: 반장 A, 부반장 B 조합과 반장 B, 부반장 A는 전혀 다른 운명이므로 각각 세어 20가지가 됨.
- 조합: 청소 당번 A와 B나 B와 A나 결국 청소하는 건 똑같으므로 절반으로 줄어들어 10가지가 됨. 인공지능이 피처(Feature) 조합을 짤 때 이 $C$(콤비네이션) 연산이 무수히 돌아감.
2. 노가다로 진리 찾기: 동전과 주사위 10만 번 조건부 확률
확률의 본질은 “무한히 많이 시도했을 때, 내가 원하는 사건이 몇 번 일어나는가?”비율임. 진짜 컴퓨터의 힘(Numpy, Pandas)을 빌려 10만 번의 쌩노가다 시뮬레이션을 돌려봄.
문제: 동전 하나와 주사위 하나를 동시에 던질 때, 동전은 앞면(Head)이면서 주사위는 홀수(1, 3, 5)가 나올 확률은?
- 수학적 정답: (동전 앞면 1/2) * (주사위 홀수 3/6) = 1/4 (25%)
🧮 판다스와 넘파이를 이용한 10만 번 시뮬레이션 실습
import pandas as pd
import numpy as np
# 1. 10만 번의 가상 실험 횟수 세팅
trials = 100000
# 2. 동전 던지기 시뮬레이션 (0: 뒷면, 1: 앞면)
# numpy의 randint(0, 2)는 0 이상 2 미만(즉 0, 1)의 랜덤 숫자 생성
coins = np.random.randint(0, 2, size=trials)
# 3. 주사위 던지기 시뮬레이션 (1부터 6까지)
# randint(1, 7)은 1 이상 7 미만(즉 1~6)의 랜덤 숫자 생성
dices = np.random.randint(1, 7, size=trials)
# 4. 판다스(Pandas) 데이터프레임으로 두 데이터를 엑셀 표처럼 예쁘게 합치기
df = pd.DataFrame({'Coin': coins, 'Dice': dices})
# 5. 우리가 원하는 조건 검색 (동전은 앞면(1) AND 주사위는 홀수(나머지 1))
condition = (df['Coin'] == 1) & (df['Dice'] % 2 != 0)
# 조건을 만족하는 행(사건)만 필터링해서 개수를 셈
success_count = len(df[condition])
# 6. 최종 확률 계산
experimental_prob = success_count / trials
print(f"10만 번 던진 결과, 조건 달성 횟수: {success_count}번")
print(f"컴퓨터가 쌩노가다로 구한 확률: {experimental_prob * 100:.2f}%")
print(f"우리가 머리로 푼 수학적 확률: 25.00%")
💡 결과 직관적 이해
돌려보면 컴퓨터가 구한 결과가 24.98% 거나 25.03% 처럼 정답(25%)에 소름 돋게 근접함. 이것이 바로 통계학의 근간인 “대수의 법칙(Law of Large Numbers)” 임. 시행 횟수를 무한에 가깝게 늘리면, 통계적 노가다 확률이 수학적 진짜 확률에 수렴하게 됨.
3. 확률밀도함수 (Probability Density Function, PDF)
앞서 본 동전이나 주사위는 “딱딱 떨어지는 불연속적인 값(1, 2, 3…)”이었음. 하지만 사람의 키나 몸무게처럼 “173.456…cm” 같이 영원히 이어지는 연속적인 값에서는 특정 숫자 하나가 콕 집혀서 나올 확률은 수학적으로 0% 임. (173.000000cm인 사람을 찾을 수 있을까?)
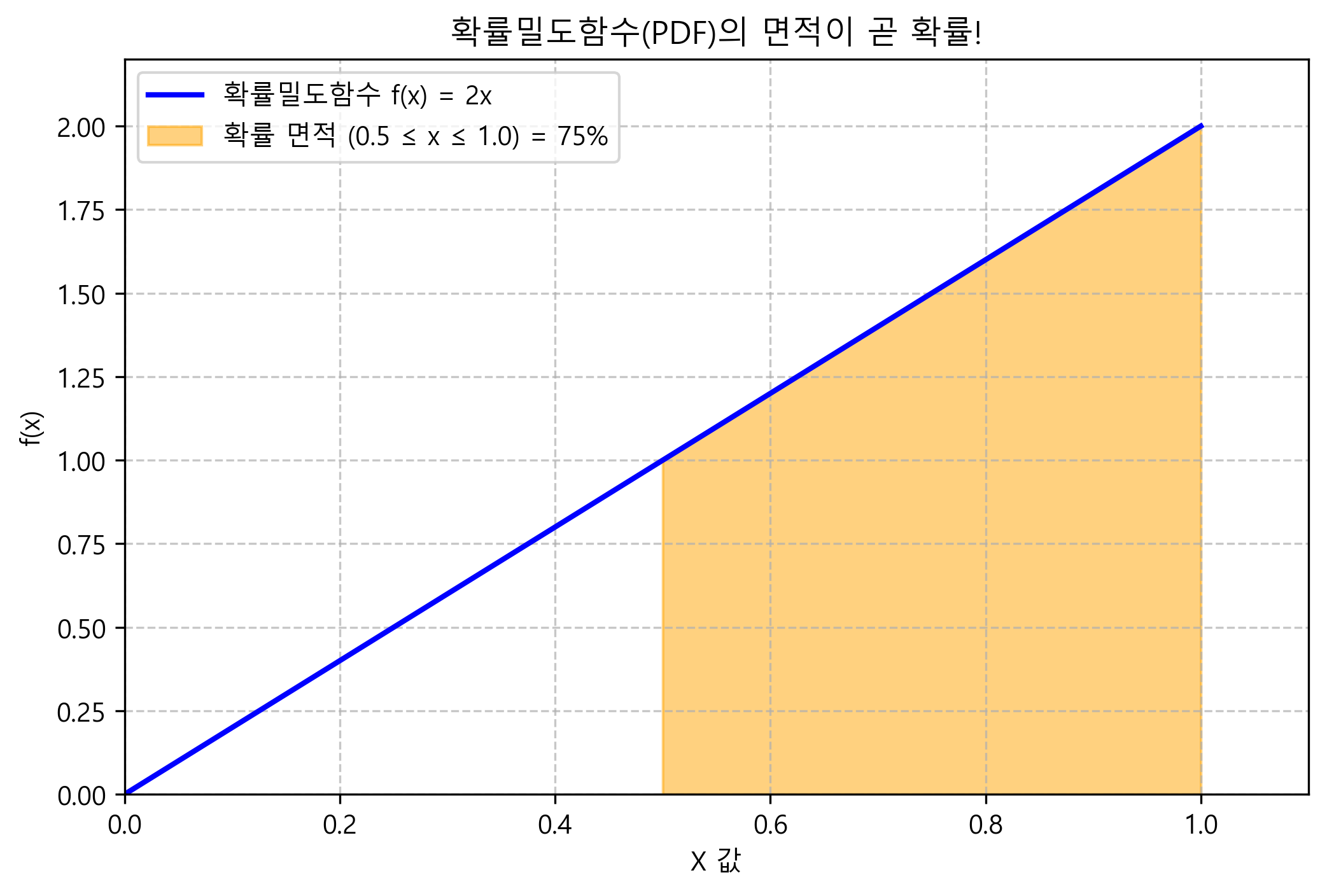
그래서 점 하나가 아니라 “범위(구간)” 를 잡고, 그 구간이 통계 그래프에서 차지하는 결과 면적(넓이) 을 확률로 정의하는 방식을 고안해 냈음. 이 넓이를 만들어내는 지붕 곡선 그래프를 확률밀도함수(PDF) 라고 부름. (정규분포 종 모양 그래프가 대표적인 PDF임)
🧮 [예제 2] 확률밀도함수 넓이(적분) 구하기 (in SageMath)
확률밀도함수 $f(x) = 2x$ (단, $0 \le x \le 1$ 구간)가 주어졌을 때, 변수 $X$가 눈금 0.5부터 1.0 사이에 떨어질 확률(넓이)을 구하는 문제임. 넓이를 구하는 거니 당연히 미적분의 적분(Integral) 기능이 출동함.
# SageMath 환경에서 실행
# 변수 x 선언
x = var('x')
# 주어진 확률밀도함수 지붕 곡선
f(x) = 2 * x
# 우리가 찾고 싶은 범위(0.5 ~ 1.0)에 맞춰 곡선 아래 면적을 적분(integrate)함!
# 이 넓이가 곧 "0.5~1.0 구간에 당첨될 확률"임.
probability_area = integrate(f(x), x, 0.5, 1.0)
print(f"X가 0.5에서 1.0 사이에 존재할 확률 (곡선 아래 넓이): {probability_area}")
# 결과: 0.75 (즉 75%)
(아래는 연속된 값의 확률을 구할 때, 지붕 곡선 아래의 특정 구간 ‘적분 면적’이 통째로 75%의 확률 덩어리가 되는 과정을 시각화한 그래프임)
4. 베이즈 정리 (Bayes’ Theorem) : “결과를 보고 원인 역추적하기”
확률론계의 셜록 홈스임. 우리가 살면서 흔히 겪는 “이미 일어난 결과(증거)”를 토대로, “도대체 왜 이런 일이 벌어졌을까?(원인)”를 역추적해서 확률을 계산하는 마법의 공식임. 스팸 메일 필터링 등 AI 추론 분야를 지배하는 핵심 뼈대임.
$P(원인 결과) = \frac{P(결과 원인) \cdot P(원인)}{P(결과)}$
🧮 [예제 4] 병원 검진 확률의 함정 (베이즈 정리 실습)
문제 상황:
- 어떤 무서운 암에 걸릴 확률(초기 원인)은 전체 인구의 1%(
0.01)임.- 병원 검사기가 진짜 암환자를 “암입니다!”라고 올바르게 진단할 확률은 90%(
0.90)임.- 하지만 건강한 사람을 실수로 “암입니다!”라고 오진할 확률도 10%(
0.10)나 됨.- 질문: 내가 병원에 가서 “암입니다!”라는 결과 통보를 받았을 때, 내가 진짜로 암에 걸려있을 확률은 과연 90%일까?
# 파이썬으로 가볍게 푸는 베이즈 정리
# 1. 뼈대(사전 지식) 세팅
# P(A): 진짜 암에 걸릴 확률 (원인)
P_A = 0.01
# P(~A): 안 걸릴 확률
P_not_A = 1 - P_A
# 2. 증거(조건부 확률) 세팅
# P(B|A): 진짜 암환자를 암이라고 진단할 확률
P_B_given_A = 0.90
# P(B|~A): 건강한데 암이라고 오진할 확률
P_B_given_not_A = 0.10
# 3. 전체 "암이라고 진단받을(B)" 확률 모으기 (분모 모델링)
# = (진짜 암인데 진단받음) + (안 걸렸는데 오진받음)
P_B = (P_B_given_A * P_A) + (P_B_given_not_A * P_not_A)
# 4. 대망의 셜록 홈스 추리: 진단받았을 때(결과B), 진짜 암일(원인A) 확률!
# P(A|B) 구하기 = ( P(B|A) * P(A) ) / P(B)
P_A_given_B = (P_B_given_A * P_A) / P_B
print(f"내가 '암입니다'라는 통보를 받았을 때, 진짜 피눈물 나는 암환자일 진짜 확률은?")
print(f"결과: {P_A_given_B * 100:.2f}%")
💡 결과 직관적 이해
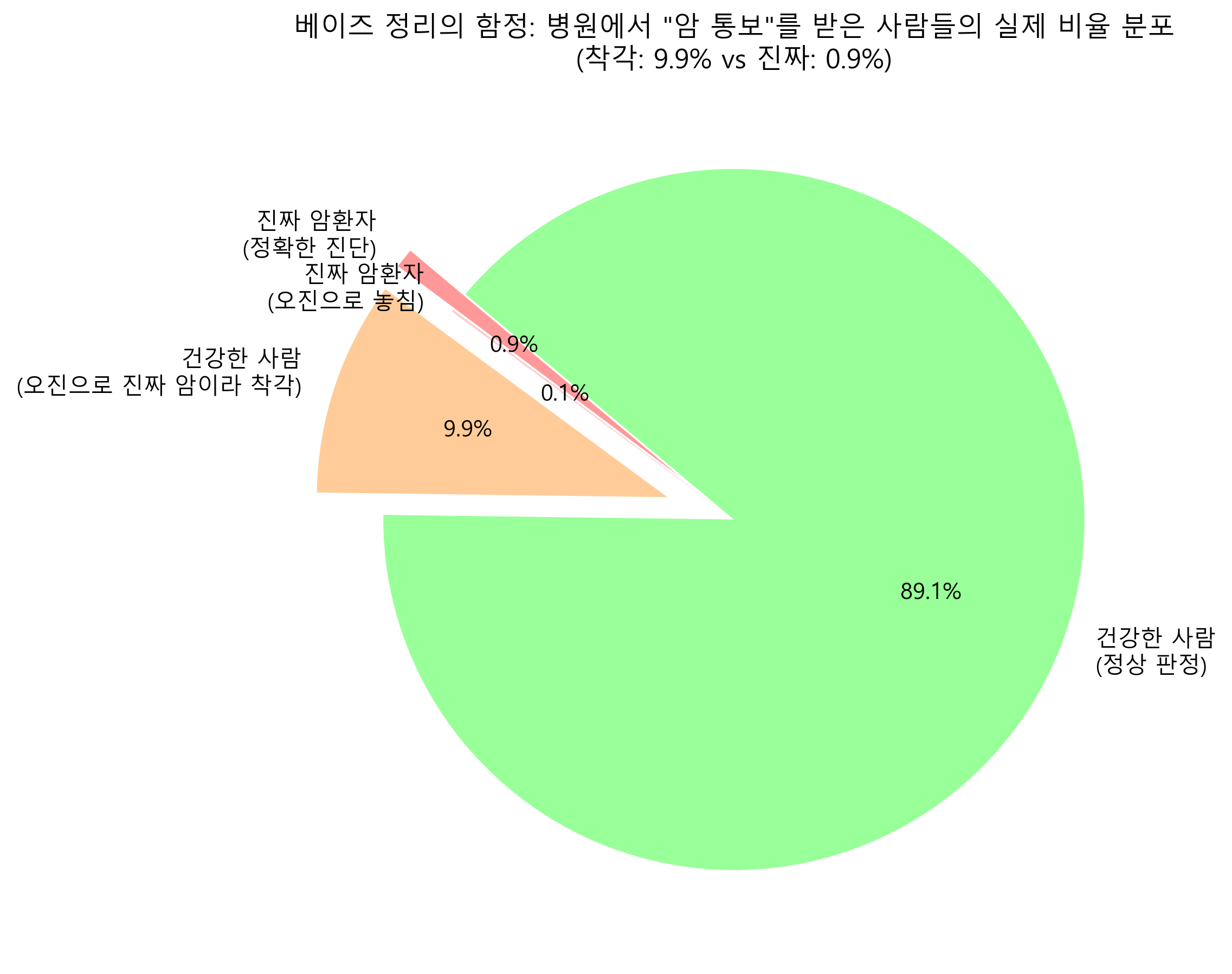
충격적이게도 진단기가 암이라고 울려도 내가 진짜 암일 확률은 고작 8.33% 밖에 안 됨!
왜냐? 세상에 암 안 걸린 건강상 사람(99%)이 압도적으로 너무 많기 때문에, 그 수많은 사람들을 오진하는 트롤링 수치(10%)의 머릿수가 진짜 1%의 암환자 머릿수를 완전히 덮어버리기 때문임. 베이즈 정리는 이런 인간의 직관적 착각을 통계로 박살 내주는 아주 훌륭한 도구임!
(아래 파이 차트를 보면, 전체 인구에서 “진단기가 암이라고 울린 사람”은 오렌지색(9.9%)과 빨간색(0.9%) 두 그룹임. 그중 내가 속한 빨간색(진짜 암) 비율은 아주 작다는 걸 직관적으로 느낄 수 있음!)
5. 데이터가 어떤 꼬라지를 하고 있나? : 기댓값, 분산, 표준편차
인공지능에 데이터를 넣기 전에, 이 데이터가 착하게 모여 있는지, 이리저리 미쳐 날뛰는지 파악해야 함.
- 기댓값 (Expected Value, 평균): 주사위를 무한히 던지면 결국 평균적으로 무슨 숫자에 수렴할까? (데이터가 모인 중심점)
- 분산 (Variance, $V$): 데이터들이 저 1번 평균(기댓값)으로부터 “얼마나 멀리 떨어져서 흩어져 있는가”를 나타내는 척도.
- 표준편차 (Standard Deviation, $\sigma$): 분산은 계산 과정에서 숫자 단위가 뻥튀기(제곱) 되어서 보기가 너무 흉악함. 그래서 다시 제곱근(루트)을 씌워서 단위를 깔끔하게 원래대로 되돌려 놓은 일상용 버전임.
🧮 [예제 1] 주사위 던지기의 기댓값과 분산 실습 (in Numpy)
1부터 6까지 적힌 완벽하게 공평한 주사위를 굴릴 때, 나올 수 있는 숫자의 기댓값 평균과 퍼져있는 정도를 구함.
import numpy as np
# 주사위의 6개 눈금 (사건 X)
dice_outcomes = np.array([1, 2, 3, 4, 5, 6])
# 각 눈금이 나올 확률 (모두 공평하게 1/6)
probabilities = np.array([1/6, 1/6, 1/6, 1/6, 1/6, 1/6])
# 1. 기댓값 (Expected Value, E(X)) = 눈금 * 확률의 총합!
expected_value = np.sum(dice_outcomes * probabilities)
print(f"주사위 눈금의 기댓값(평균): {expected_value:.2f}")
# 2. 분산 (Variance, V(X)) 구할 때 쓸 공식: E(X^2) - {E(X)}^2
# 먼저 각각의 눈금을 제곱한 뒤 확률을 곱해서 더함 (제곱의 평균)
expected_value_sq = np.sum((dice_outcomes ** 2) * probabilities)
# (제곱의 평균) - (평균의 제곱) 공식 적용!
variance = expected_value_sq - (expected_value ** 2)
print(f"주사위 눈금의 분산: {variance:.2f} (숫자가 뻥튀기됨)")
# 3. 표준편차 (Standard Deviation)
# 뻥튀기된 분산에 다시 루트(np.sqrt) 씌워서 원상복구
std_dev = np.sqrt(variance)
print(f"주사위 눈금의 예쁜 표준편차: {std_dev:.2f}")
💡 결과 직관적 이해
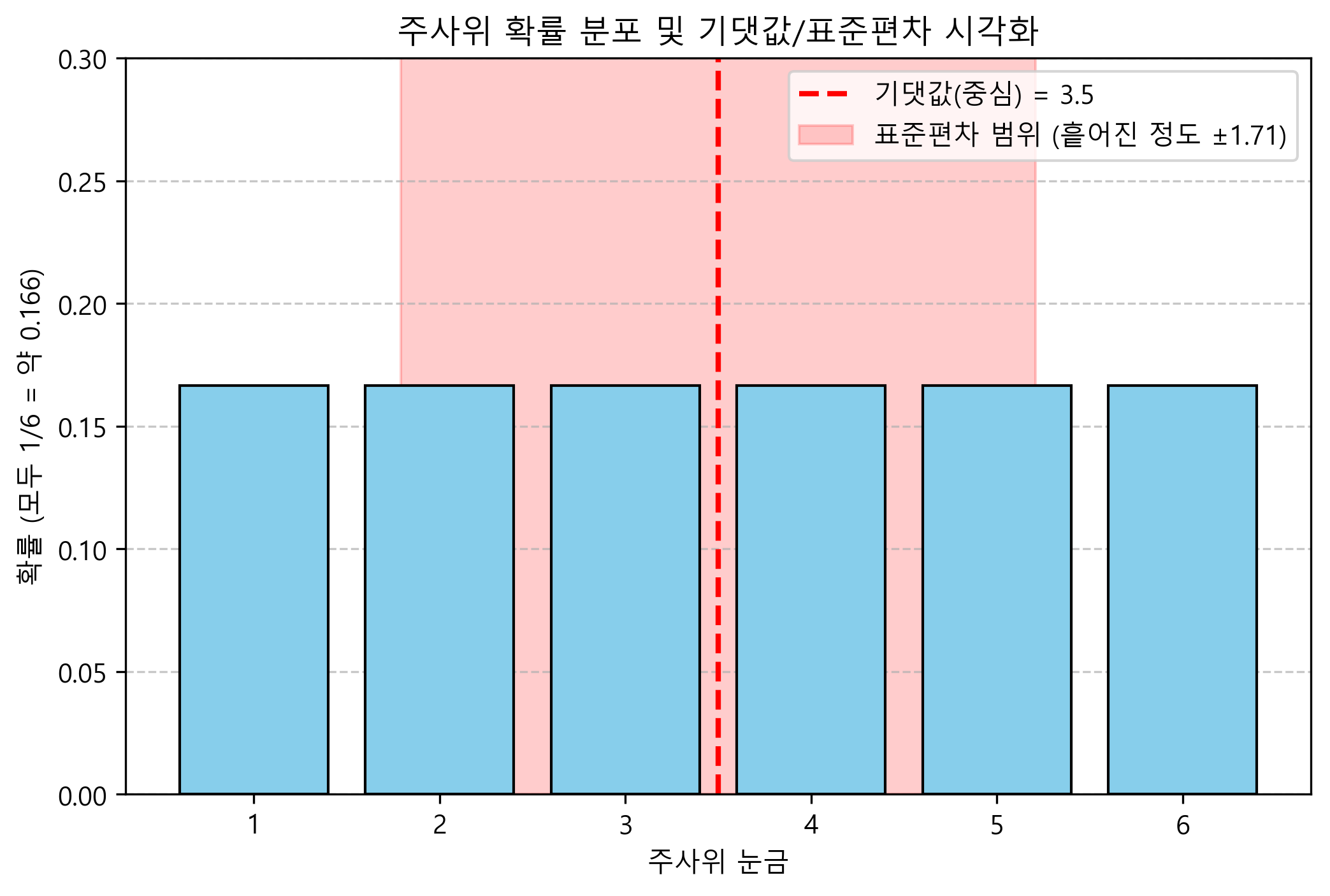
- 기댓값 3.5: 주사위를 수도 없이 던지면 결국 눈금의 평균은 3과 4의 딱 중간인 3.5 언저리에서 놀게 됨.
- 표준편차 1.71: 주사위를 던졌을 때 나오는 눈금들은 대충 중심 평균(3.5)으로부터 평균적으로 약 1.71칸 정도씩 오르락내리락 벗어나는 경향을 가지고 흩어져 있다는 뜻임!
(아래는 주사위 눈금의 평등한 확률 분포와, 중심을 꽉 잡고 있는 빨간색 기댓값(평균) 선, 그리고 그 주위로 오르락내리락 흩어지는 분산/표준편차의 반경을 시각화한 것임)
🎯 오늘의 요약 (Summary)
- 순열과 조합: 순서가 중요한 줄 세우기는 빡센 순열(P), 대충 한 무더기로 팀만 뽑는 건 널널한 조합(C).
- 확률밀도함수(PDF): 몸무게처럼 영원히 이어지는 연속된 값에서는 특정 점 하나를 찍으면 확률이 0임. 대신 구간 넓이(적분)를 구해서 확률 범위를 정의함.
- 베이즈 정리: “도대체 저 결과는 어떤 원인에서 파생된 걸까?” 인간의 착각을 교정하고 원인을 확률로 역추적하는 셜록 홈스 추리 기법.
- 기댓값/분산/표준편차: 내 데이터가 평균(기댓값) 주변에 얌전히 모여 있는지, 미친 듯이 멀리(분산, 표준편차) 흩어져서 AI 모델을 헷갈리게 하는지 판단하는 나침반.
Comments