[인공지능 수학] 로지스틱 회귀, 피셔의 선형판별분석(LDA), 인공신경망과 라그랑주 승수법 총정리
📌 오늘의 학습 목표
데이터 분포를 배웠다면, 이제 그 데이터로 선을 긋고(회귀), 분류하고(판별), 학습(신경망)할 차례임! 이번 포스트에서는 기계학습의 근간이 되는 분류 알고리즘들과 최적화 기법을 일상생활의 재미있는 비유로 재구조화하여 내 것으로 만들어 봄.
- 로지스틱 회귀 vs 선형 회귀: 무한정 뻗어 나가는 직선과, 0과 1 사이로 예쁘게 꺾이는 S자 곡선의 차이를
Plotly로 시각화하여 이해함.- Fisher의 선형판별분석(LDA): 두 개 이상의 그룹을 가장 확실하게 쪼개버리는 ‘최적의 선명한 기준선’을 긋는 원리를 파악함.
- 신경망과 기계학습(ML) 정의: 기계가 학습한다는 것의 진짜 의미와 뇌 세포를 모방한 신경망의 개념을 정리함.
- 인공신경망(ANN)과 오차역전파법: 인공지능이 자신의 실수를 깨닫고 거꾸로 돌아가며 뇌파(가중치)를 수정하는 학습 과정을 톺아봄.
- 라그랑주 승수법: “예산은 한정되어 있는데, 만족도는 최대로 뽑고 싶다!” 같은 제약 조건 속 최적화 문제의 수학적 아이디어를 정복함.
1. 선형 회귀 vs 로지스틱 회귀 (Linear vs Logistic)
인공지능 예측 모델의 쌍두마차임. 이름은 둘 다 “회귀(Regression)”지만, 쓰임새는 하늘과 땅 차이임.
- 선형 회귀 (Linear Regression): “숫자(연속값)” 를 에측함.
- “공부를 10시간 하면, 내일 수능 점수는 몇 점일까?” 👉 (예측값: 85.3점, 92점 등 무한정 뻗어나감)
- 그래프 모양: 끝없이 뻗어 올라가는 꼿꼿한 직선 대각선(/) 임.
- 로지스틱 회귀 (Logistic Regression): 이름만 회귀지 사실은 “분류(분류기)” 임.
- “공부를 10시간 하면, 내일 수능에 합격(1)할까 불합격(0)할까?” 👉 (결과: 0 아니면 1)
- 선형 회귀처럼 꼿꼿한 직선을 써버리면, 공부 100시간 한 사람의 합격 확률이 500%를 뚫고 우주로 날아가 버리는 심각한 모순이 생김. (확률은 무조건 0%~100% 안에서 놀아야 함!)
- 해결책: 무한대로 치솟는 선형 직선의 위아래를 꾹 눌러서, 0과 1 사이에서만 놀도록 찌그러뜨린 S자 곡선(시그모이드 함수) 을 도입함!
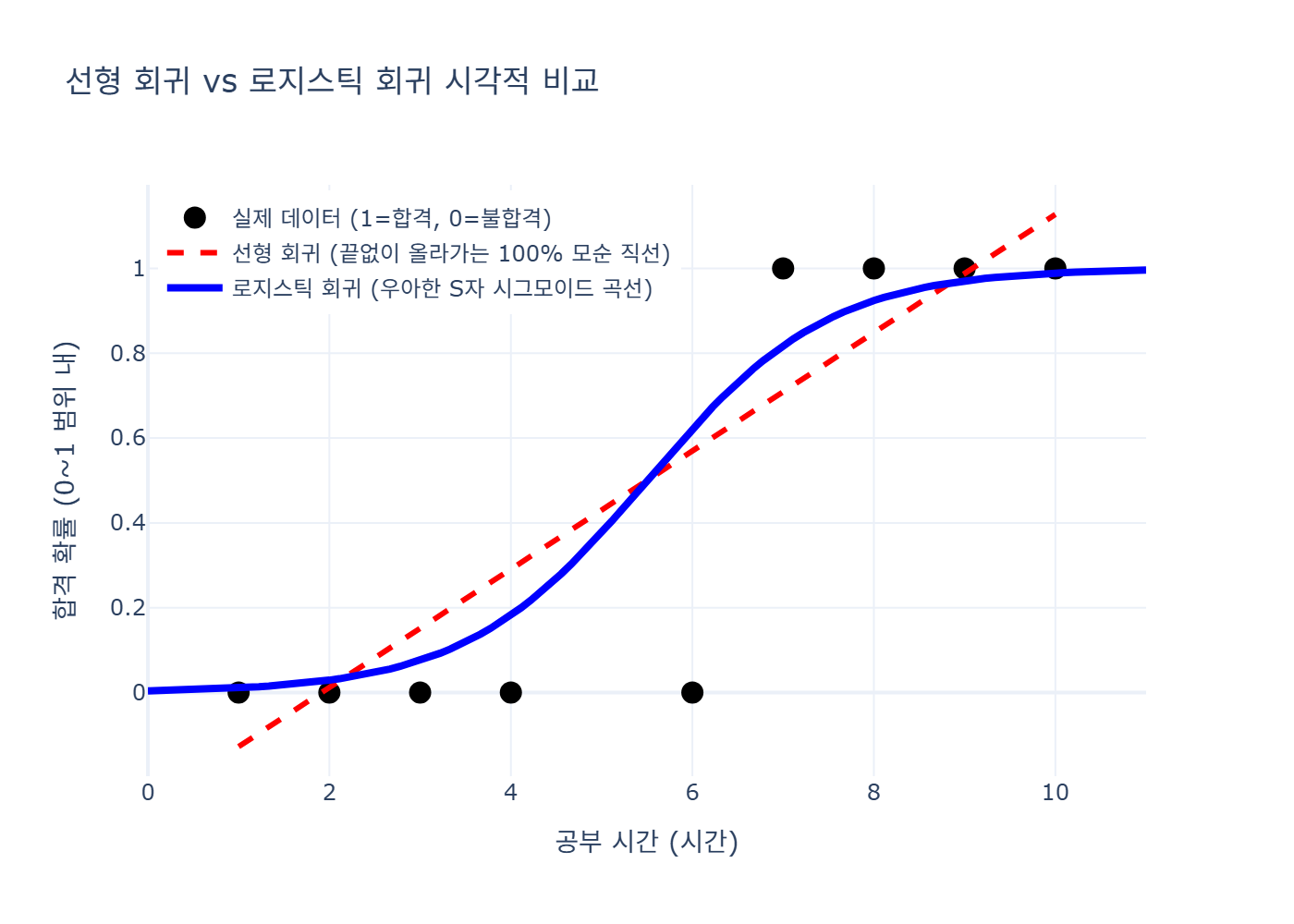
📈 [Plotly 실습] 선형 회귀와 로지스틱 회귀의 시각적 비교
Plotly 패키지를 이용해 두 회귀선의 치명적인 차이를 파이썬 코드로 그려봄. (직선은 1(100%)을 뚫고 나가지만, S자 곡선은 1에 우아하게 수렴함)
import numpy as np
import pandas as pd
import plotly.graph_objects as go
# 1. 공부 시간에 따른 합격(1)/불합격(0) 가상 데이터 생성
study_hours = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
pass_fail = np.array([0, 0, 0, 0, 1, 0, 1, 1, 1, 1]) # 5시간 이상부터 합격자가 많아짐
# 2. 선형 회귀 (단순 1차 방정식: y = ax + b) 계산 (Numpy polyfit)
coef_linear = np.polyfit(study_hours, pass_fail, 1) # 1차식 선형 피팅
linear_y = np.polyval(coef_linear, study_hours)
# 3. 로지스틱 회귀 (S자 곡선, Sigmoid 함수: 1 / (1 + e^(-x)))
# 직관을 위해 수동으로 S자 함수(시그모이드)를 데이터에 맞게 대충 피팅함
def sigmoid(x):
return 1 / (1 + np.exp(-(x - 5.5))) # 5.5시간 근처에서 절반(0.5) 확률로 꺾임
logistic_y = sigmoid(study_hours)
# 4. Plotly를 활용한 반응형 인터랙티브 그래프 그리기!
fig = go.Figure()
# 실제 합격/불합격 산점도 점 찍기
fig.add_trace(go.Scatter(x=study_hours, y=pass_fail, mode='markers',
name='실제 데이터 (1=합격, 0=불합격)', marker=dict(size=10, color='black')))
# 선형 회귀 직선 그리기 (100%를 뚫고 나가버리는 모순 발생!)
fig.add_trace(go.Scatter(x=study_hours, y=linear_y, mode='lines',
name='선형 회귀 (끝없이 올라가는 멍청한 직선)', line=dict(color='red', dash='dash')))
# 로지스틱 회귀 곡선 그리기 (0과 1 사이에서 예쁘게 수렴함!)
fig.add_trace(go.Scatter(x=study_hours, y=logistic_y, mode='lines',
name='로지스틱 회귀 (우아한 S자 시그모이드)', line=dict(color='blue', width=3)))
fig.update_layout(title="선형 회귀 vs 로지스틱 회귀 차이점 비교",
xaxis_title="공부 시간 (시간)", yaxis_title="합격 확률 (0~1)",
template="plotly_white")
fig.show()
# (블로그에는 아래에 이 Plotly 코드가 렌더링한 S자 곡선 캡처본이 들어감!)
(아래 그래프 캡처본을 보면, 빨간색 점선(선형)은 공부를 10시간 하면 합격 확률이 120%가 넘는다고 헛소리를 함. 반면 파란색 S자 실선(로지스틱)은 아주 예쁘게 0%와 100% 사이 안착하는 것을 볼 수 있음!)
2. Fisher의 선형판별분석 (Linear Discriminant Analysis, LDA)
만약 사과, 귤, 바나나 3가지 과일(다중 클래스)의 데이터가 3차원 공간에 마구 섞여 있다면, 이들을 가장 잘 구분 짓는 기준선(경계선)을 어떻게 그어줄 수 있을까?
피셔(Fisher)라는 수학자가 고안한 선형판별분석(LDA) 은 아주 단순하지만 강력한 두 가지 철학을 가짐.
- “클래스(과일 종) 끼리 뭉쳐 있는 중심점들은 최대한 멀찌감치 떨어뜨려 놔라!” (클래스 간 분산 최대화)
- “같은 클래스(같은 사과) 끼리는 오밀조밀하게 꽉꽉 모여 있게 압축해라!” (클래스 내 분산 최소화)
즉, 데이터들을 특정 축(선) 위로 그림자 지게(정사영) 비췄을 때, 사과 그림자 무더기와 귤 그림자 무더기가 서로 겹치지 않고 가장 뚜렷하게 떨어져 보이게 만드는 “사진이 제일 잘 찍히는 최적의 각도(선)” 를 찾는 알고리즘임! (주성분 분석 PCA가 그냥 분산만 넓게 퍼뜨리는 거라면, LDA는 ‘정답 라벨(사과냐 배냐)’을 알기 때문에 완전히 분류를 목적으로 축을 찾음)
3. 기계학습(Machine Learning)과 인공신경망 정의
전통적인 프로그래밍과 기계학습의 가장 큰 차이는 “누가 규칙을 찾아내느냐” 임.
🤖 1. 기계학습 (Machine Learning)
과거의 컴퓨터 프로그램은 개발자가 일일이 “사과는 빨간색이고 둥글다”라는 조건문(if-else 규칙) 코드를 짜서 입력을 주면, 결과(사과)를 뱉었음. 하지만 기계학습은 데이터(수만 장의 사진) 와 정답(이건 사과야) 만 쿨하게 컴퓨터한테 무더기로 던져줌. 그러면 기계가 알아서 그 수만 장의 사진들의 공통된 패턴이나 픽셀 쪼가리의 수학적 특성(가중치 값)을 스스로 빚고 깎아내어 “빨갛고 둥근 패턴의 규칙”을 스스로 찾아내는(학습하는) 알고리즘의 총칭임.
- 지도 학습 (Supervised): 정답지(Label)를 같이 주면서 공부시킴 (예: 회귀, 분류).
- 비지도 학습 (Unsupervised): 정답 없이 데이터만 줘서 무더기 속에서 특징을 분류해 보라 함 (예: 클러스터링, PCA).
🧠 2. 인공신경망 (Artificial Neural Network, ANN)
기계학습의 수많은 기법 중에서, 오직 인간의 뇌세포(뉴런, Neuron) 가 작동하는 생물학적 구조를 고대로 베껴와서 컴퓨터의 수학 함수로 뻥튀기한 딥러닝(Deep Learning)의 근본 뼈대 모델임.
우리의 뇌 세포 하나하나는 이렇게 동작함:
- 가지돌기 (Dendrite): 앞 뉴런으로부터 찌릿찌릿한 전기 신호(입력 데이터 $x$)를 받아들임.
- 시냅스 (Synapse): 들어온 신호가 얼마나 중요한지 결정함 (컴퓨터에서는 이게 핵심인 가중치 $W$, Weight 임! 중요하면 숫자를 곱해서 증폭시키고, 헛소리면 줄여버림).
- 신경세포체 (Soma): 가중치가 곱해진 신호들을 몸통에 한데 모아 싹 다 합침 ($\sum Wx + b$). 여기서 $b$는 기본적으로 흥분하는 정도인 편향(Bias) 임.
- 축삭돌기 (Axon): 모아진 총합 전기 신호가 일정 역치(기준치)를 넘으면 다음 세포로 신호를 빵 터뜨려 보냄! 이게 바로 컴퓨터의 활성화 함수(Activation Function, 앞서 배운 시그모이드/ReLU 등) 임.
이런 뉴런 함수를 수백만, 수십억 개씩 거미줄처럼 층(Layer - 입력층, 은닉층, 출력층)으로 겹겹이 쌓아 올려 거대한 “인공지능 두뇌”를 만든 것을 인공신경망이라고 함.
4. 인공신경망 뇌세포의 진화 과정: 오차역전파법 (Backpropagation)
인터넷에 수많은 AI 짤방이나 글을 보면 신경망이 “스스로 공부하여 똑똑해진다”라고 함. 도대체 쇳덩어리 컴퓨터가 어떻게 ‘공부’라는 걸 할까? 그 핵심 비밀이 바로 오차역전파법(Backpropagation) 임. 이름이 살벌하지만 뜻은 아주 매력적임.
🧠 오차역전파법 작동 원리 3스텝
- 순전파 (Forward Propagation - 일단 질러보기):
- 입력 데이터(개 사진)를 신경망에 막 집어넣음.
- 뉴런들이 대충 아무렇게나 설정된 초기 뇌파(가중치)로 “이거 고양이 아님? 80% 확신!” 하면서 정답을 일단 뱉어봄.
- 오차(Error / Loss) 계산 (현타의 시간):
- 정답지(개)와 모델이 찍은 답(고양이)을 비교함.
- “아놔, 고양이라고 80%나 질렀는데 완전 틀렸네? 오차(Loss)가 엄청나게 크군…” 하고 뼈저리게 자신의 실수를 수치화해 반성함.
- 오차역전파 (Backward Propagation - 족집게 오답 노트 수정):
- 이 뼈저린 오차(실패) 값을 들고, 컴퓨터가 뒤에서부터 앞쪽으로 거꾸로(역, Backward) 되돌아감(전파, Propagation)!
- 출력층에서 뱉은 실수를, 중간 전달자인 은닉층 뉴런들에게 미적분(편미분)을 써서 “야! 너네들 중 아까 누가 고양이라고 우기는 데 가장 큰 비중(가중치)을 미쳤어? 너네 연결고리 숫자 좀 줄여!” 하고 뇌파(가중치)를 실시간으로 조율하고 깎아냄.
이 “질러보고 -> 틀린 거 반성하고 -> 뒤로 돌아가며 미분으로 수치 깎기”의 과정을 10만 번, 100만 번 무한 반복하면서 최적의 두뇌 상태(가중치)로 수렴하는 과정! 이것이 바로 인공지능이 “학습(Learning)”한다고 부르는 것의 진짜 실체임!
5. 라그랑주 승수법 (Lagrange Multipliers)
고등학교 수학 시간에 미분으로 기울기가 0인 지점을 찾아 함수의 최댓값, 최솟값을 구했던 기억이 날 것임. 하지만 현실 세계의 인공지능 최적화는 그렇게 만만치 않은 “제약 조건” 들이 덕지덕지 붙어있음.
- “내 예산은 딱 10만 원뿐인데(제약 조건), 여친을 가장 행복하게 해 줄 데이트 코스(최댓값)는 멀까?”
- “내 컴퓨터 서버 메모리는 16GB뿐인데(제약 조건), AI 모델의 성능 에러율(최솟값)을 가장 낮추려면 어떻게 세팅해야 할까?”
이렇게 족쇄(제약식 $g(x,y)=0$)가 채워진 상태에서 어떤 함수($f(x,y)$)의 최고봉이나 최저점을 찾고 싶을 때, 수학자 라그랑주가 개발한 핵폭탄급 우회로가 바로 라그랑주 승수법임.
💡 핵심 아이디어 컨셉 (비유적 이해)
- 제약 조건 없이 가장 높은 곳으로 올라가려는 힘 (원래 함수의 등고선).
- 제약 조건의 경계선을 따라가려는 힘 (족쇄 함수의 등고선).
- 이 두 힘(기울기, Gradient)이 서로 수직 단층을 이루며 딱 평행하게 부딪혀 입맞춤(접하는) 하는 지점이 존재함. 이 지점이 바로 족쇄를 뚫고 갈 수 있는 한계이자 우리가 찾던 최적의 타협점(최댓값/최솟값) 임!
- 수학적으로는 마법의 람다($\lambda$, 라그랑주 승수)를 붙여서 새로운 변종 함수 식 하나(라그랑주 함수 $\mathcal{L}$)로 합친 다음, 평소처럼 가볍게 편미분 해서 0이 되는 곳을 찾으면 족쇄 속의 보물을 아주 쉽게 찾을 수 있음! (이 기법은 훗날 서포트 벡터 머신(SVM)이라는 위대한 머신러닝 알고리즘의 심장으로 작동함)
🎯 오늘의 요약 (Summary)
- 로지스틱 회귀: 예측 결과가 100%를 뚫고 고장 나는 선형 직선의 한계를 극복하기 위해, 0~1 사이로 확률을 찌그러뜨리는 궁극의 S자(시그모이드) 분류 함수.
- Fisher의 LDA: 다중 클래스 데이터를 나눌 때, “같은 놈끼리는 제일 뭉치고, 다른 놈 무리와는 제일 멀어지는” 최적의 사진 촬영 각도(사영 축)를 찾는 기법.
- 신경망과 기계학습: 기계가 정답 코딩 없이 데이터 속에서 스스로 규칙과 패턴(가중치)을 체득하는 뇌세포 모방 컴퓨터 함수 뭉치.
- 오차역전파 (Backpropagation): 일단 결과를 뱉은 뒤 정답과 비교한 크나큰 ‘실수(오차)’를 안고 뇌세포들을 거꾸로 거슬러 올라가며 미분으로 범인을 찾아 가중치 선을 잘라내는(깎는) 위대한 AI 공부 비법.
- 라그랑주 승수법: 족쇄(제약 조건)가 채워진 상태에서 최댓값/최솟값을 구할 때, 두 기울기가 평행하게 뽀뽀하는 접점을 찾아 람다($\lambda$)라는 치트키로 단박에 최적의 해를 찾아내는 우회로 마법.
Comments