[LangChain] RAG 완전 정복 — 초보자도 이해하는 심화 가이드
“왜?” 를 먼저 설명하는 가이드임. 코드를 외우기 전에 개념을 이해하면 응용이 쉬워짐. 모든 기술 개념에는 일상생활 비유를 함께 제공함.
시각화 다이어그램 한눈에 보기
| 다이어그램 | 설명 |
|---|---|
| ① AI 에이전트 전체 구조 | LLM + 툴 + 미들웨어 + 메모리의 관계 |
| ② 메시지 흐름 | “서울 날씨 어때요?” 처리 과정 |
| ③ 미들웨어 레이어 | @before_agent → LLM → @after_agent |
| ④ RAG 파이프라인 | Load → Split → Embed → Store → Generate |
| ⑤ 메모리 + 가드레일 | 단기/장기 메모리 + 결정론적/모델 기반 가드레일 |
목차
- Step 1: AI 에이전트란 무엇인가
- Step 2: LangChain 기초
- Step 3: 에이전트 베이직
- Step 4: 어드밴스드 에이전트
- Step 5: RAG — 자체 데이터로 AI 강화하기
- Step 6: 전체 통합 — 최종 에이전트 아키텍처
- Step 7: 자주 묻는 질문과 트러블슈팅
- 전체 요약 — 핵심 개념 30초 리뷰
Step 1: AI 에이전트란 무엇인가
1-1. LLM의 등장과 한계
2022년 ChatGPT가 등장하면서 세상은 LLM(Large Language Model, 대형 언어 모델)에 열광함. LLM은 엄청난 양의 텍스트 데이터를 학습해서 사람처럼 글을 쓰고 질문에 답하는 AI임.
하지만 LLM에는 근본적인 한계가 있음.
한계 1: 학습 시점이 고정되어 있음
LLM은 특정 날짜까지의 데이터만 학습함. GPT-5 Nano의 경우 2025년 8월 7일까지의 데이터만 알고 있음. 마치 2025년 8월에 폐간된 백과사전처럼, 그 이후 일어난 일은 전혀 모름.
[비유]
LLM = 2025년 8월에 인쇄된 백과사전
→ 2025년 9월 이후 뉴스? 모름
→ 오늘 날씨? 모름
→ 어제 주가? 모름
한계 2: 우리 회사 내부 데이터는 모름
LLM은 인터넷에 공개된 데이터로만 학습됨. 우리 회사의 고객 데이터, 내부 문서, 영업 자료 같은 비공개 데이터는 당연히 모름.
[비유]
LLM = 공공 도서관의 책만 읽은 직원
→ 우리 회사 내부 매뉴얼? 모름
→ 고객 주문 현황? 모름
→ 작년 매출 데이터? 모름
한계 3: 한 번에 처리할 수 있는 정보량에 한계가 있음
GPT-5는 한 번에 약 128,000 토큰(대략 책 1권 분량)만 입력받을 수 있음. 회사 전체 문서를 한꺼번에 넣는 것은 불가능함.
1-2. 그래서 등장한 AI 에이전트
이런 한계를 극복하기 위해 AI 에이전트가 등장함.
에이전트의 핵심 아이디어는 간단함.
“LLM이 모르는 것이 있으면, 직접 찾아오면 됨”
[비유]
기존 LLM = 모든 것을 머릿속에서만 해결하는 직원
→ 2025년 8월 이후는 모름
AI 에이전트 = 인터넷 검색도 하고, DB도 조회하고,
계산기도 쓰는 스마트한 직원
→ 모르면 도구를 써서 알아옴
에이전트 = LLM + 도구(Tool)
LLM이 두뇌 역할을 하고, 도구가 LLM이 할 수 없는 일(실시간 검색, DB 조회, 계산 등)을 대신함.
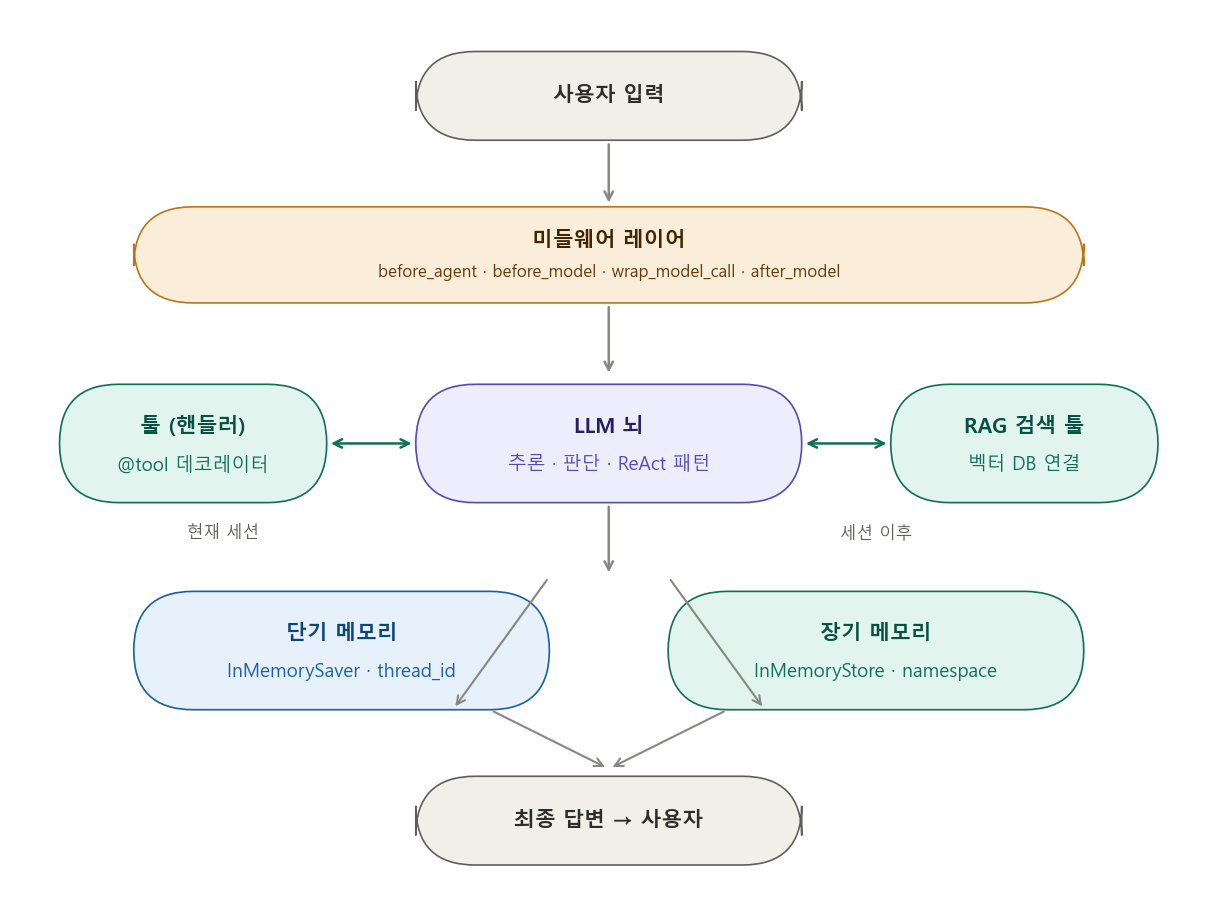
1-3. LLM 기반 애플리케이션 vs 에이전트 — 핵심 차이
두 가지를 명확히 구분해야 에이전트를 제대로 이해할 수 있음.
LLM 기반 애플리케이션 — “개발자가 모든 것을 정함”
개발자가 미리 코드로 작성:
"날씨" 키워드 감지 → 날씨 API 호출
"주문" 키워드 감지 → 주문 DB 조회
"뉴스" 키워드 감지 → 뉴스 API 호출
문제점: 예상하지 못한 입력이 들어오면 작동하지 않음.
# 날씨 챗봇 예시 (LLM 기반 애플리케이션)
user_input = "날씨 어때?" # → 키워드 매칭 실패! 파이프라인 작동 안 함
# "오늘", "서울", "날씨" 키워드가 없으면 조건문에 걸리지 않음
AI 에이전트 — “LLM이 스스로 판단함”
사용자: "날씨 어때?"
LLM 추론:
1. "이건 날씨 관련 질문이다"
2. "한국어니까 서울 날씨를 물어보는 것 같다"
3. "오늘 날씨를 알려주려면 날씨 API 툴을 써야겠다"
4. 날씨 API 호출 (파라미터: location="서울")
5. 결과 받아서 자연스럽게 답변 생성
개발자가 “날씨 어때?”라는 케이스를 미리 코드로 작성하지 않아도 됨. LLM이 스스로 판단함. 이것이 바로 동적(Dynamic) 시스템임.
Step 2: LangChain 기초
2-1. LangChain이란
LangChain은 AI 에이전트를 쉽게 만들 수 있게 도와주는 프레임워크임.
[비유]
프레임워크 = 건물의 철골 구조
철골 구조 없이 건물 짓기: 처음부터 모든 것을 직접 만들어야 함 (매우 복잡)
철골 구조 있을 때: 뼈대에 살만 붙이면 됨 (훨씬 간단)
LangChain 없이: OpenAI API 직접 호출, 메시지 관리, 에러 처리... 모두 직접 구현
LangChain 있을 때: 준비된 기능들을 조합해서 에이전트 빠르게 구축
2025년 10월 20일, LangChain이 버전 1.0으로 업데이트되면서 에이전트 구축에 더욱 집중하게 됨.
2-2. 모델 초기화 — 기초 중의 기초
LangChain에서 LLM을 사용하려면 먼저 모델 객체를 만들어야 함.
import os
os.environ["OPENAI_API_KEY"] = "sk-..." # API 키 등록
from langchain.chat_models import init_chat_model
# 모델 객체 생성
model = init_chat_model("gpt-5-nano")
“객체를 만든다”는 것이 무슨 의미인가?
[비유]
model = init_chat_model("gpt-5-nano")
이것은 마치 직원을 고용하는 것과 같음.
"gpt-5-nano"라는 직원을 고용해서
"model"이라는 이름표를 달아줬다고 생각할 것.
이제 model.invoke("질문")은
"model이라는 직원에게 질문한다"는 의미임.
파라미터 설명
model = init_chat_model(
"gpt-5-nano",
# temperature: 답변의 창의성 조절 (0.0 ~ 1.0)
temperature=0.7,
# 0에 가까울수록: "오늘 날씨" → 항상 비슷한 답변 (안정적)
# 1에 가까울수록: "시 한 편 써줘" → 매번 다른 답변 (창의적)
# max_tokens: 답변의 최대 길이
max_tokens=1000,
# 1 토큰 ≈ 영어 단어 0.75개 ≈ 한글 0.5글자
# 1000 토큰 ≈ 한글 약 500글자 분량
# timeout: 몇 초 동안 기다릴지
timeout=30,
# OpenAI 서버가 느릴 때 무한정 기다리는 것을 방지
# max_retries: 실패 시 몇 번 재시도할지
max_retries=3
# 네트워크 오류가 생겨도 자동으로 3번 재시도
)
temperature 더 쉽게 이해하기
LLM이 답변을 만드는 과정:
다음 단어 후보: ["맑", "흐림", "비", "눈"] 각각 확률 부여
temperature=0.0 (항상 확률 1등 선택)
→ "맑" (70%) 항상 선택
→ 매번 같은 답변, 예측 가능, 논리적
temperature=1.0 (낮은 확률 단어도 선택 가능)
→ "눈" (5%) 가끔 선택
→ 매번 다른 답변, 창의적, 예측 불가능
[언제 어떻게 쓸까?]
코딩 도움, 수학 풀이, 데이터 분석 → temperature: 0.0 ~ 0.3
일반 대화, 고객 응대 → temperature: 0.3 ~ 0.5
소설 쓰기, 광고 카피, 브레인스토밍 → temperature: 0.6 ~ 0.9
2-3. invoke, stream, batch — 세 가지 실행 방법
invoke — 질문 하나에 답변 하나
response = model.invoke("랭체인이 뭔가요?")
print(response.content) # 실제 답변 텍스트
print(response.usage_metadata) # 토큰 사용량 정보
# → {'input_tokens': 12, 'output_tokens': 156, 'total_tokens': 168}
[비유]
invoke = 카카오톡에서 메시지 보내고 답장 기다리기
→ 메시지 전송 → 답장이 올 때까지 기다림 → 답장 수신
stream — 답변이 타이핑되듯 실시간으로 나옴
for chunk in model.stream("랭체인이 뭔가요?"):
print(chunk.text, end="")
# "랭" "체" "인" "은" " " "대" "형" ...이 순서대로 출력됨
[비유]
stream = ChatGPT 사용할 때처럼 답변이 흘러나오는 것
invoke: 답변이 완성될 때까지 기다렸다가 한 번에 표시
→ 사용자가 10초를 빈 화면만 보다가 갑자기 긴 답변이 나타남
→ UX(사용자 경험) 나쁨
stream: 만들어지는 단어를 실시간으로 표시
→ 사용자가 답변이 나오는 것을 보면서 읽기 시작
→ UX 좋음 (ChatGPT가 이 방식을 사용)
batch — 여러 질문을 한 번에 병렬 처리
inputs = [
"과적합이 뭔가요?",
"앵무새 털이 화려한 이유는?",
"AI 에이전트 서비스는 뭔가요?"
]
responses = model.batch(inputs)
for r in responses:
print(r.content)
print("---")
[비유]
batch = 식당에서 주문받기
invoke 방식: 손님1 주문받기 → 손님1 음식 나올 때까지 기다리기 → 손님2 주문받기...
→ 비효율적! 한 번에 한 명씩 처리
batch 방식: 손님1, 2, 3 동시에 주문받기 → 주방에서 동시에 요리 → 동시에 서빙
→ 효율적! 시간 단축, 비용 절감
2-4. 메시지 3종류 완전 이해
LLM과 대화할 때 메시지는 3가지 종류가 있음. 이 개념을 확실히 이해하는 것이 에이전트 구축의 첫걸음임.
┌─────────────────────────────────────────────────┐
│ LLM에 전달되는 메시지 구조 │
│ │
│ SystemMessage ← 개발자가 작성, AI 역할 설정 │
│ HumanMessage ← 사용자 입력 │
│ AIMessage ← AI가 생성한 답변 │
│ HumanMessage ← 사용자 다음 입력 │
│ AIMessage ← AI 다음 답변 │
│ ... │
└─────────────────────────────────────────────────┘
[비유]
SystemMessage = 회사에서 직원에게 주는 업무 지침서
"당신은 고객 서비스 담당입니다. 항상 친절하게..."
→ 고객(사용자)은 보지 못함
HumanMessage = 고객의 문의
"제품이 언제 배송되나요?"
AIMessage = 직원(AI)의 답변
"주문일로부터 3-5 영업일 내에 배송됩니다"
실제 코드로 대화 맥락 유지하기
from langchain.schema import SystemMessage, HumanMessage, AIMessage
messages = [
SystemMessage("당신은 친절한 AI 비서입니다. 사용자 이름을 기억하세요."),
HumanMessage("안녕하세요, 저는 종민입니다"),
]
response1 = model.invoke(messages)
print(response1.content)
# → "안녕하세요, 종민님! 무엇을 도와드릴까요?"
messages.append(AIMessage(response1.content)) # AI 답변을 기록에 추가
messages.append(HumanMessage("제 이름이 뭐라고 했죠?"))
response2 = model.invoke(messages)
print(response2.content)
# → "종민이라고 하셨습니다!"
[왜 이게 동작하는가?]
LLM은 사실 "이전 대화를 기억"하지 않음.
매번 독립적으로 동작함.
하지만 이전 대화를 messages 리스트에 담아서
매번 전부 다시 전달하기 때문에
"기억하는 것처럼" 보이는 것임.
마치:
- 기억상실증 직원에게 매번 회의록 전체를 다시 읽어주는 것
- 그래서 직원은 마치 기억하는 것처럼 일할 수 있음
딕셔너리 형태로도 동일하게 작동
messages = [
{"role": "system", "content": "당신은 친절한 AI 비서입니다."},
{"role": "user", "content": "안녕하세요, 저는 종민입니다"},
{"role": "assistant", "content": "안녕하세요, 종민님!"},
{"role": "user", "content": "제 이름이 뭐죠?"},
]
# role에는 "system", "user"(또는 "human"), "assistant"(또는 "ai") 사용 가능
2-5. 구조화된 출력 (Structured Output)
AI의 답변을 약속된 데이터 형태로 강제하는 기능임.
왜 필요한가?
일반 AI 답변 (자연어):
"인셉션은 2010년 개봉한 크리스토퍼 놀란 감독의 SF 스릴러로,
꿈속의 꿈을 배경으로 한 독창적인 스토리로 높은 평가를 받았습니다.
IMDb 평점은 8.8점입니다."
→ 이 텍스트에서 "감독 이름"을 추출하려면? 복잡한 파싱 필요
→ DB에 저장하려면? 수동으로 분리해야 함
→ 다음 시스템에 전달하려면? 형식이 안 맞을 수 있음
구조화된 AI 답변 (Structured Output):
{
"title": "인셉션",
"year": 2010,
"director": "크리스토퍼 놀란",
"rating": 8.8
}
→ 감독 이름: result.director (즉시 접근 가능)
→ DB 저장: 바로 INSERT 가능
→ 다음 시스템 전달: 형식이 명확함
[실생활 비유]
구조화된 출력 = 병원 진료 기록지
일반 텍스트: "환자는 38.5도 열이 있고 3일째 기침을 하고 있으며
인후통도 호소하고 있습니다. 독감 의심됩니다."
구조화된 출력:
┌──────────┬──────────────────┐
│ 체온 │ 38.5도 │
│ 증상 기간 │ 3일 │
│ 주요 증상 │ 기침, 인후통 │
│ 의심 진단 │ 독감 │
└──────────┴──────────────────┘
→ 진료 기록지 형태가 있어야 다른 의사도 빠르게 파악하고
보험 청구, 약 처방 등 후속 작업이 가능함
Pydantic으로 스키마 정의
from pydantic import BaseModel, Field
class Movie(BaseModel):
title: str = Field(description="영화 제목")
year: int = Field(description="개봉 연도 (숫자만)")
director: str = Field(description="감독 이름")
rating: float = Field(description="평점 (0.0 ~ 10.0)")
structured_model = model.with_structured_output(Movie)
result = structured_model.invoke("영화 인셉션에 대해 설명해줘")
print(result.title) # "인셉션"
print(result.year) # 2010
print(result.director) # "크리스토퍼 놀란"
print(result.rating) # 8.8
주의사항: JSON 스키마 방식은 영어만
# ❌ 잘못된 예 (한글 키 → OpenAI 에러)
json_schema = {
"title": "영화정보",
"properties": {
"제목": {"type": "string"}, # 한글 키 → 에러!
"감독": {"type": "string"}
}
}
# ✅ 올바른 예 (영어 키만 사용)
json_schema = {
"title": "Movie",
"properties": {
"title": {"type": "string", "description": "영화 제목"},
"director": {"type": "string", "description": "감독 이름"}
}
}
[왜 영어만 가능한가?]
LangChain이 이 스키마를 OpenAI API에 직접 전달함.
OpenAI 서버에서 키 이름을 영어/숫자/언더스코어/_/대시-만 허용함.
Pydantic 방식은 LangChain이 내부에서 변환해주므로 한글 설명(description)은 가능함.
2-6. LangSmith — 에이전트의 블랙박스 열기
LangSmith는 에이전트 내부에서 무슨 일이 일어나는지 시각적으로 추적하는 도구임.
[비유]
에이전트 = 비행기
LangSmith = 비행기의 블랙박스 + 관제탑 모니터
블랙박스 없이: 뭔가 잘못됐을 때 원인 파악 불가
블랙박스 있을 때: 정확히 어느 순간 무슨 일이 있었는지 파악 가능
LangSmith 없이: AI가 왜 이상한 답변을 했는지 모름
LangSmith 있을 때: 어떤 입력이 들어갔고, 어떤 툴을 호출했고,
어디서 시간이 걸렸는지 한눈에 파악 가능
설정 방법과 순서가 중요한 이유
# ⚠️ 반드시 이 순서를 지켜야 함!
# 1단계: 환경 변수 먼저 설정
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "ls-..."
os.environ["LANGCHAIN_PROJECT"] = "my-first-agent"
os.environ["OPENAI_API_KEY"] = "sk-..."
# 2단계: 그 다음에 모듈 임포트
from langchain.chat_models import init_chat_model
# ← 이 줄에서 LangChain이 환경 변수를 읽어서 LangSmith 연결 설정
# 만약 환경 변수가 나중에 설정되면 연결이 안 됨!
[왜 순서가 중요한가?]
식당에 입장할 때 예약 번호를 줘야 테이블을 배정받는 것처럼,
LangChain 모듈은 임포트되는 순간 "LangSmith에 연결할까?"를 결정함.
이미 모듈이 임포트된 후에 API 키를 넣어봤자 무시됨.
그래서 코랩에서 LangSmith 설정을 추가하려면:
1. 상단 메뉴 → 런타임 → 세션 종료
2. 다시 처음부터 실행 (환경 변수 먼저, 임포트 나중)
LangSmith에서 확인할 수 있는 것들
smith.langchain.com → 프로젝트 클릭 → 실행 기록
각 실행에 대해:
┌─────────────────────────────────────────────────┐
│ Input │ "ARK 펀드 테슬라 비중이 얼마야?" │
│ Output │ "12.26%입니다" │
│ Latency │ 2.34초 (어디서 시간이 걸렸는지 확인) │
│ Tokens │ Input: 45, Output: 89, Total: 134 │
│ Cost │ $0.000023 │
│ Status │ 성공 / 실패 │
│ 세부 단계 │ 모델 호출 → 툴 호출 → 모델 호출 │
└─────────────────────────────────────────────────┘
Step 3: 에이전트 베이직
3-1. 툴(Tool) — 에이전트의 팔다리
에이전트에서 LLM이 두뇌라면, 툴은 팔다리임. LLM 혼자서는 할 수 없는 일(실시간 검색, 계산, DB 조회 등)을 툴이 대신함.
[비유]
에이전트 = 수술실의 외과의사
LLM(두뇌) = 의사의 지식과 판단력
"지금 봉합이 필요하다"고 판단
툴(팔다리) = 수술 도구들
- 메스 (절개 도구)
- 실과 바늘 (봉합 도구)
- 혈압계 (측정 도구)
의사가 "봉합하자"고 생각만 해서는 안 됨
→ 실제로 봉합 도구(툴)를 사용해야 봉합이 이루어짐
툴 만드는 4단계
from langchain.tools import tool
# 1단계: 함수 이름 짓기 (역할이 명확해야 함)
def get_weather(
# 2단계: 타입 힌팅 (LLM이 어떤 값을 넣어야 하는지 알 수 있음)
location: str # 입력: 지역명 (문자열)
) -> str: # 출력: 날씨 정보 (문자열)
# 3단계: 독스트링 (LLM이 이 툴을 언제 쓸지 판단하는 기준!)
"""특정 지역의 현재 날씨 정보를 제공합니다.
날씨, 기온, 강수량 등을 알고 싶을 때 사용하세요."""
# 4단계: 실제 로직
return f"{location}의 날씨는 맑고 영하 2도입니다"
# @tool 데코레이터로 LangChain 툴로 변환
@tool
def get_weather(location: str) -> str:
"""특정 지역의 현재 날씨 정보를 제공합니다."""
return f"{location}의 날씨는 맑고 영하 2도입니다"
독스트링이 왜 중요한가?
[매우 중요한 개념!]
LLM이 툴을 호출할지 결정할 때, 독스트링을 읽고 판단함.
사용자: "오늘 부산 날씨 어때?"
LLM 내부 판단 과정:
1. "날씨 관련 질문이다"
2. 내가 가진 툴 목록 확인:
- get_weather: "특정 지역의 현재 날씨 정보를 제공합니다. 날씨, 기온..."
- search_news: "최신 뉴스를 검색합니다..."
- calculate: "수학 계산을 수행합니다..."
3. "get_weather가 딱 맞다! 이걸 써야겠다"
4. 파라미터: location="부산" (스스로 작성)
5. get_weather("부산") 호출
만약 독스트링이 없거나 불명확하면?
→ LLM이 어떤 툴을 써야 할지 잘못 판단하거나 아예 안 씀
→ 에이전트 성능 저하
[결론] 독스트링은 LLM에게 주는 사용 설명서임.
더 구체적일수록 LLM이 정확하게 툴을 사용함.
3-2. 에이전트 내부 동작 완전 분석
에이전트가 실행될 때 내부에서 어떤 일이 일어나는지 단계별로 살펴봄.
from langchain.agents import create_agent
agent = create_agent(model, tools=[get_weather])
result = agent.invoke({
"messages": [{"role": "user", "content": "서울 날씨 어때요?"}]
})
# 전체 메시지 흐름 출력
for i, msg in enumerate(result["messages"]):
print(f"\n[메시지 {i}] {type(msg).__name__}")
if hasattr(msg, 'content') and msg.content:
print(f" 내용: {msg.content}")
if hasattr(msg, 'tool_calls') and msg.tool_calls:
print(f" 툴 호출: {msg.tool_calls}")
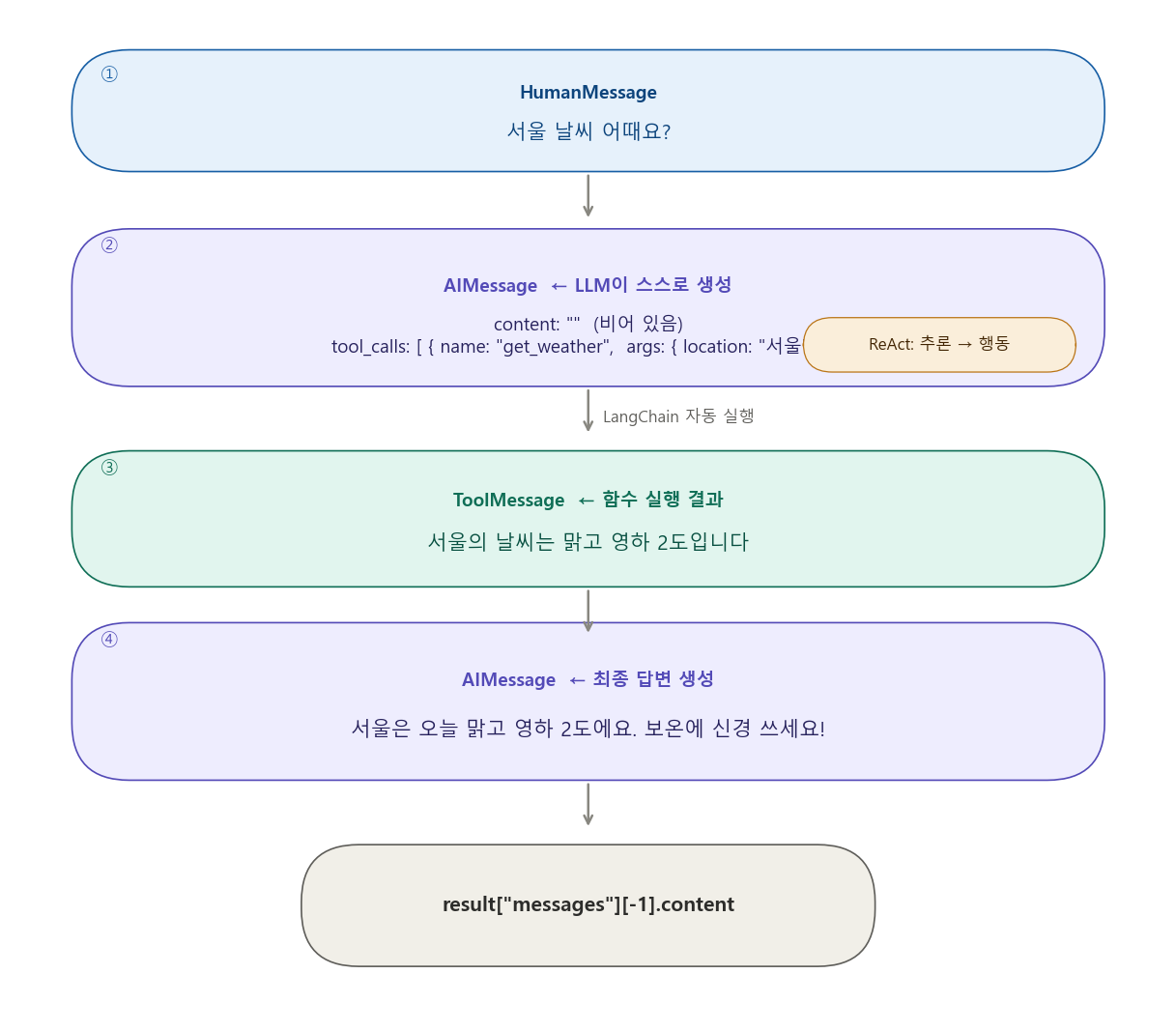
실제 출력 결과 분석
[메시지 0] HumanMessage
내용: 서울 날씨 어때요?
↑ 우리가 입력한 것
[메시지 1] AIMessage
내용: (비어 있음!)
툴 호출: [{'name': 'get_weather', 'args': {'location': '서울'}, 'id': '...'}]
↑ AI가 스스로 작성한 것
- content가 비어 있음 = "나 직접 답 안 함, 툴 쓸게"
- tool_calls = "get_weather를 location='서울'로 호출하겠다"
- 이 모든 것을 AI가 스스로 판단하고 작성!
[메시지 2] ToolMessage
내용: 서울의 날씨는 맑고 영하 2도입니다
↑ get_weather("서울") 함수가 실행된 결과
LangChain이 메시지 1의 tool_calls를 보고 자동으로 함수 실행
[메시지 3] AIMessage
내용: 서울은 오늘 맑고 기온은 영하 2도예요. 외출하실 땐 보온에 신경 쓰세요! 🧥
↑ 메시지 0~2를 모두 읽고 최종 답변 생성
가장 중요한 포인트: 메시지 1은 AI가 스스로 작성했음
[이것이 에이전트의 핵심임]
메시지 1의 tool_calls:
{
"name": "get_weather", ← AI가 스스로 선택
"args": {"location": "서울"} ← AI가 스스로 작성
}
개발자가 "서울이라고 입력하면 location='서울'로 설정해"라고
코드를 짠 것이 아님.
LLM이 "서울 날씨 어때요?"를 읽고:
1. "이건 날씨 질문이다" (추론)
2. "get_weather 툴이 있다" (판단)
3. "'서울'을 location에 넣어야겠다" (행동)
이 모든 것을 AI가 스스로 함.
이것이 바로 Reason(추론) → Act(행동)이며,
이를 줄여서 ReAct라고 부름.
LangChain 내부 자동화 로직
LangChain은 이런 규칙을 내부에 구현해 놨음:
AIMessage.content == "" 이고
AIMessage.tool_calls에 값이 있으면
→ tool_calls[0]["name"]에 해당하는 함수를 자동 실행
→ 실행 결과를 ToolMessage로 변환
→ 다시 AI 호출
이 덕분에 개발자는 "언제 툴을 호출할지"를 코드로 짤 필요가 없음.
AI가 알아서 판단하고, LangChain이 자동으로 실행함.
3-3. 시스템 프롬프트 — AI에게 역할 부여하기
에이전트를 만들 때 시스템 프롬프트를 주입해서 AI의 행동 방식을 제어할 수 있음.
agent = create_agent(
model,
tools=[add, multiply, divide],
system_prompt="당신은 유능한 수학 선생님입니다. 사칙연산 요청 시 반드시 툴을 이용하시오."
)
왜 시스템 프롬프트가 필요한가?
[실제 문제 상황]
에이전트에 덧셈, 곱셈, 나눗셈 툴을 만들어줬음.
"42 + 3 * 23은 얼마야?"라고 물어봤더니...
툴 호출 없이 바로 답변: "111입니다"
왜 이런 일이?
→ LLM은 간단한 계산 정도는 스스로 할 수 있다고 판단
→ "굳이 툴을 쓸 필요 없겠는걸?" 하고 직접 계산
하지만 원하는 것은:
→ 반드시 툴을 통해 계산하는 것 (정확도 보장)
→ 어떤 계산 과정을 거쳤는지 추적 가능하게 하기 위함
해결책: 시스템 프롬프트로 강제
→ "사칙연산은 반드시 툴을 이용하시오"
시스템 프롬프트 작성 팁
명확하게: "날씨 관련 질문에는 항상 get_weather 툴을 사용하세요"
구체적으로: "답변은 반드시 3줄 이내로 요약하세요"
제약 설정: "투자 조언은 절대 하지 마세요"
역할 부여: "당신은 10년 경력의 Python 개발자입니다"
언어 설정: "항상 한국어로 답변하세요"
3-4. 단기 메모리 (Short-term Memory)
메모리 없는 에이전트의 문제
agent = create_agent(model, tools=[])
result1 = agent.invoke({"messages": [{"role": "user", "content": "저는 종민입니다"}]})
# → "반갑습니다, 종민님!"
result2 = agent.invoke({"messages": [{"role": "user", "content": "제 이름이 뭐죠?"}]})
# → "죄송하지만 이 대화에서는 이름을 들은 적이 없습니다"
# ← 앞의 대화를 전혀 모름!
[왜 모르는가?]
result1과 result2는 완전히 독립적인 호출임.
각 invoke() 호출은 완전히 새로운 대화를 시작함.
마치:
- 기억상실증에 걸린 직원에게 하루에 두 번 전화하는 것
- 두 번째 전화 때 첫 번째 통화 내용을 전혀 기억 못 함
체크포인터(Checkpointer)로 메모리 구현
from langgraph.checkpoint.memory import InMemorySaver
memory = InMemorySaver()
agent = create_agent(
model,
tools=[],
checkpointer=memory
)
config_A = {"configurable": {"thread_id": "conversation_A"}}
config_B = {"configurable": {"thread_id": "conversation_B"}}
# 세션 A - 첫 번째 대화
result1 = agent.invoke(
{"messages": [{"role": "user", "content": "저는 종민입니다"}]},
config=config_A
)
# 세션 A - 두 번째 대화 (이전 내용 기억!)
result2 = agent.invoke(
{"messages": [{"role": "user", "content": "제 이름이 뭐죠?"}]},
config=config_A # ← 같은 thread_id!
)
print(result2["messages"][-1].content)
# → "종민이라고 하셨습니다!"
# 세션 B - 완전히 새로운 대화 (A의 내용 모름)
result3 = agent.invoke(
{"messages": [{"role": "user", "content": "제 이름이 뭐죠?"}]},
config=config_B # ← 다른 thread_id!
)
print(result3["messages"][-1].content)
# → "아직 이름을 말씀해주지 않으셨는데요"
[thread_id 개념 이해]
thread_id = 대화방 번호
카카오톡 채팅방을 생각해볼 것:
- 채팅방 #1 (thread_id: "A"): 친구와의 대화 기록
- 채팅방 #2 (thread_id: "B"): 가족과의 대화 기록
- 채팅방 #1에서 친구와 나눈 얘기를 채팅방 #2에서는 모름
실제 서비스에서:
- thread_id = 사용자 ID + 채팅방 ID 조합
- 예: "user_123_chatroom_456"
InMemorySaver의 한계와 실제 서비스
InMemorySaver는 현재 실행 중인 프로그램의 메모리에만 저장됨.
→ 서버 재시작 시 모든 대화 기록 삭제
→ 개발/테스트 환경에만 적합
실제 서비스에서는:
→ PostgresSaver (PostgreSQL 기반 영구 저장)
→ RedisSaver (Redis 기반 빠른 저장)
등을 사용함.
3-5. 미들웨어 — 에이전트의 보안문과 품질관리
미들웨어는 에이전트 내부에 체크포인트를 설치하는 것과 같음.
[비유]
에이전트 = 공항
미들웨어 없는 에이전트:
입구 → 바로 비행기 탑승
→ 위험물 반입 가능, 여권 확인 없음 (매우 위험!)
미들웨어 있는 에이전트:
입구 → [보안 검색대] → [여권 심사] → [탑승구 확인] → 비행기 탑승
↑ 금지물 차단 ↑ 신원 확인 ↑ 최종 점검
각 검색대 = 미들웨어 레이어
1. LLM Tool Emulator — “아직 없는 기능 먼저 테스트”
from langchain.agents.middleware import LLMToolEmulator
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""이메일을 전송합니다"""
pass # 로직 미구현
@tool
def read_email(limit: int = 10) -> str:
"""이메일을 조회합니다"""
pass # 로직 미구현
agent = create_agent(
model,
tools=[send_email, read_email],
middleware=[
LLMToolEmulator(model=init_chat_model("gpt-5-nano"))
]
)
[작동 방식]
LLMToolEmulator 있을 때:
AI → "send_email 호출" → Emulator가 가로챔
→ "이 툴이 실행됐다면 어떤 결과가 나왔을까?" AI가 추측
→ 가상의 현실적인 결과 생성
예: "이메일이 kim@company.com에 성공적으로 전송되었습니다.
전송 시각: 2025-11-26 14:32:15"
[언제 유용한가?]
→ API 키를 아직 발급받지 못했을 때
→ API가 유료라서 개발 중에는 실제 호출을 피하고 싶을 때
→ 전체 에이전트 흐름을 먼저 테스트하고 싶을 때
2. TodoList Middleware — “복잡한 업무를 체계적으로”
from langchain.agents.middleware import TodoListMiddleware
agent = create_agent(
model,
tools=[read_email, send_email],
middleware=[
LLMToolEmulator(model=init_chat_model("gpt-5-nano")),
TodoListMiddleware()
]
)
[작동 방식]
TodoListMiddleware 있을 때:
AI가 먼저 투두리스트를 자동 생성:
Step 1: 메일함 확인 → [진행 중]
Step 2: 메일 내용 요약 → [대기]
Step 3: 답장 작성 → [대기]
Step 4: 답장 전송 → [대기]
Step 5: 완료 보고 → [대기]
[장점]
→ 복잡한 업무를 빠짐없이 처리
→ 어느 단계까지 진행됐는지 추적 가능
→ 중간에 실패해도 어디서 실패했는지 파악 가능
3. Human In The Loop — “중요한 순간에 사람 개입”
[실생활 비유]
Human In The Loop 없을 때:
사용자: "거래처에 답장해줘"
AI: (바로 이메일 전송) → 내용이 잘못됐을 수도 있는데 이미 보내버림!
Human In The Loop 있을 때:
사용자: "거래처에 답장해줘"
AI: "이렇게 답장을 작성했습니다: [내용]
보내도 될까요? (승인/수정/거절)"
사용자: 확인 후 "승인" 또는 "수정" 또는 "거절"
AI: 사용자 결정에 따라 처리
→ 중요한 작업 전에 사람이 최종 확인!
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model,
tools=[read_email, send_email],
checkpointer=InMemorySaver(), # ← 반드시 필요!
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"read_email": False,
"send_email": True,
"allow_decisions": ["approve", "edit", "reject"]
}
)
]
)
[왜 checkpointer가 반드시 필요한가?]
사람의 개입으로 대화가 중단됨.
사용자가 "좋아, 보내줘"라고 다시 입력했을 때
에이전트가 앞선 맥락을 기억해야 함.
checkpointer 없이는 이 맥락이 끊겨버림.
4. PII Detection — “개인정보 자동 보호”
PII(Personally Identifiable Information) 예시:
이름, 주민등록번호, 전화번호, 이메일, 신용카드 번호, IP 주소 등
from langchain.agents.middleware import PIIMiddleware
import re
agent = create_agent(
model,
tools=[save_feedback],
middleware=[
PIIMiddleware(types=["email"], strategy="redact", apply_to_input=True),
PIIMiddleware(types=["credit_card"], strategy="mask", apply_to_input=True),
# 커스텀: 한국 전화번호
PIIMiddleware(
types=["korean_phone"],
detector=re.compile(r"010-\d{3,4}-\d{4}"),
strategy="mask",
apply_to_input=True
),
]
)
[strategy 옵션 비교]
"redact": "내 번호는 010-1234-5678" → "내 번호는 [REDACTED]"
"mask": "내 번호는 010-1234-5678" → "내 번호는 010-****-5678"
"block": 에러 발생! 요청 자체를 거부
"hash": "내 번호는 010-1234-5678" → "내 번호는 a3f8c2d1e9b4..." (해시값)
[apply_to 옵션]
apply_to_input=True → LLM에 들어가기 전에 처리
apply_to_output=True → LLM 답변에서 처리
apply_to_tool_result=True → 툴 반환값에서 처리
Step 4: 어드밴스드 에이전트
4-1. 컨텍스트 엔지니어링 — 왜 중요한가
[핵심 개념]
LLM의 컨텍스트 윈도우 = AI의 "현재 작업 공간"
마치 책상 위 공간과 같음:
- 책상이 너무 비어 있으면 → 필요한 자료 없어서 일 못 함
- 책상이 너무 가득 차 있으면 → 어느 자료가 중요한지 모름, 비효율적
- 딱 필요한 자료만 적절히 → 최고 효율로 일할 수 있음
이 "책상 위 자료 배치 최적화"가 바로 컨텍스트 엔지니어링임.
GPT-5의 컨텍스트 윈도우 = 128,000 토큰
= A4 용지 약 250장 분량
= 책 1권 정도
이 공간에 무엇을 어떻게 넣느냐가 에이전트 성능을 결정함.
4-2. 런타임(Runtime)과 스테이트(State)
런타임 — “에이전트 작업실의 공유 자료 보관함”
Runtime 구성:
┌────────────────────────────────────────────┐
│ Runtime │
│ │
│ ┌──────────────────────────────────────┐ │
│ │ Context (변하지 않는 고정 정보) │ │
│ │ - user_id: "user_123" │ │
│ │ - app_name: "edu_agent" │ │
│ │ - db_url: "mysql://..." │ │
│ └──────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────┐ │
│ │ Store (변할 수 있는 장기 메모리) │ │
│ │ - "파이썬 선호함" │ │
│ │ - "A 강의 수강 완료, 90점" │ │
│ │ - "에이전트에 관심 있음" │ │
│ └──────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────┐ │
│ │ StreamWriter (실시간 이벤트) │ │
│ │ - LangGraph에서 주로 사용 │ │
│ └──────────────────────────────────────┘ │
└────────────────────────────────────────────┘
스테이트 — “에이전트가 만들어낸 결과물”
result = agent.invoke(...)
result["messages"] = 지금까지의 모든 대화 기록
[HumanMessage, AIMessage, ToolMessage, AIMessage...]
4-3. 미들웨어 작성 방법 두 가지
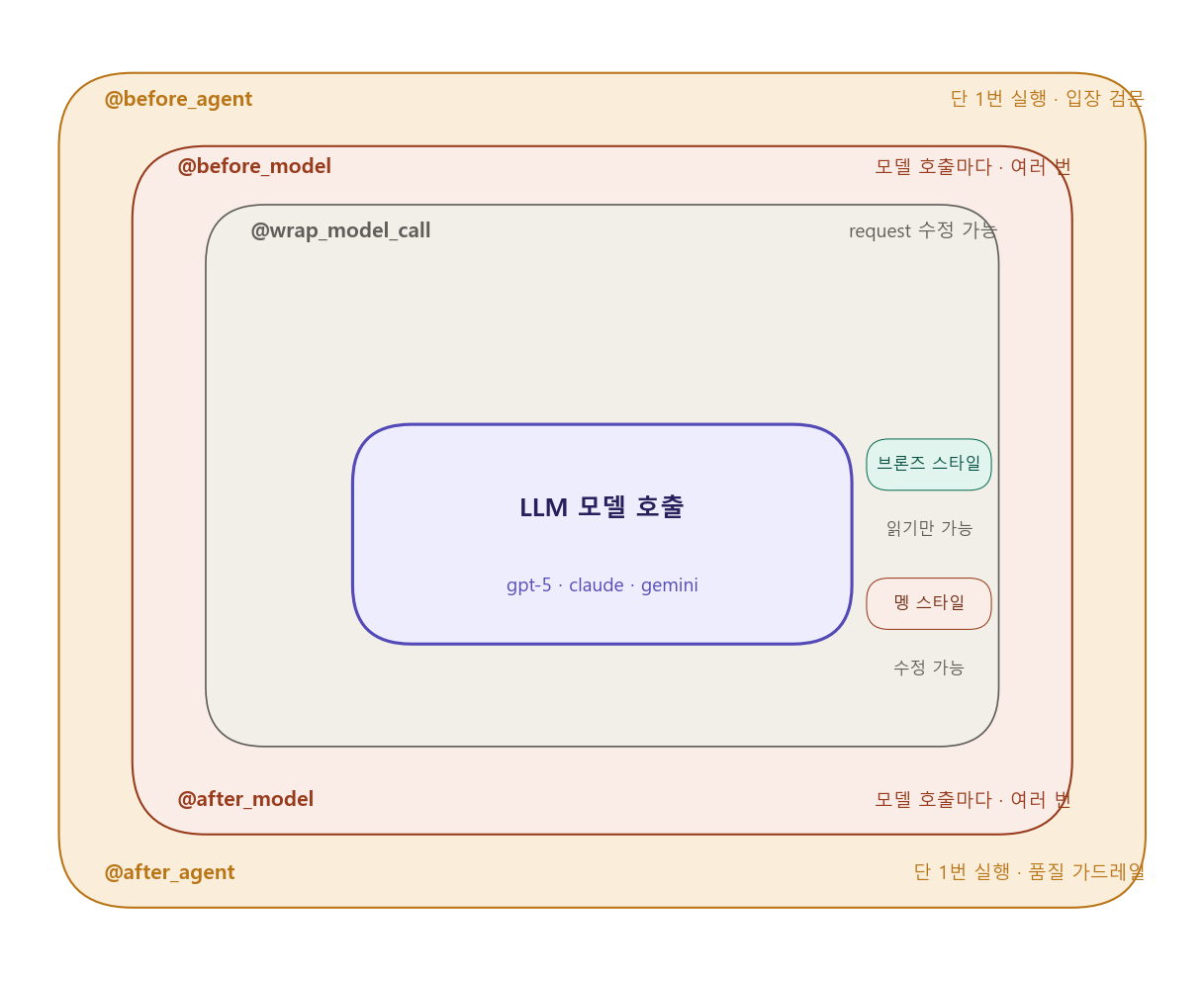
노드 스타일 훅 — “특정 순간에 카메라 달기”
CCTV처럼 특정 순간을 감시함. 보기만 하고, 막거나 수정하지 않음.
@before_agent = 에이전트 입장 CCTV (단 1번)
@before_model = 모델 호출 전마다 CCTV (여러 번)
@after_model = 모델 호출 후마다 CCTV (여러 번)
@after_agent = 에이전트 퇴장 CCTV (단 1번)
from langchain.agents.middleware import before_model, after_agent
@before_model
def log_context(state, runtime):
msg_count = len(state.get("messages", []))
username = runtime.context.username
print(f"[로그] 모델 호출 전 - 메시지 {msg_count}개, 사용자: {username}")
# 아무것도 반환하지 않음 = 그냥 지나침
@after_agent
def log_final_answer(state, runtime):
final_msg = state["messages"][-1].content
print(f"[로그] 최종 답변: {final_msg[:50]}...")
랩 스타일 훅 — “보안 검색대 설치하기”
공항 보안 검색대처럼 물건을 검사하고 수정할 수 있음.
@wrap_model_call = 모델에게 전달되는 "짐"을 검사하고 수정
@wrap_tool_call = 툴에게 전달되는 "짐"을 검사하고 수정
from langchain.agents.middleware import wrap_model_call
@wrap_model_call
def inject_user_context(request, handler):
username = request.runtime.context.username
if username:
new_sys_prompt = f"현재 대화 중인 사용자 이름: {username}"
new_request = request.override(system_prompt=new_sys_prompt)
return handler(new_request)
return handler(request)
[request.override() 이해하기]
request = 모델에게 보내는 "편지 봉투"
- 안에 들어있는 것: 시스템 프롬프트, 메시지들, 모델 설정 등
request.override(system_prompt="새로운 내용")
= 봉투를 열어서 시스템 프롬프트만 교체하고 다시 봉함
= 나머지 내용은 그대로 유지
new_request = 수정된 새 봉투 (원본 봉투는 변경 안 됨)
return handler(new_request) = 수정된 봉투를 모델에게 전달
4-4. 가드레일 — 신뢰할 수 있는 에이전트 만들기
[왜 가드레일이 중요한가?]
POC (Proof of Concept, 개념 증명)
= "이거 만들 수 있어?" 를 증명하는 단계
POV (Proof of Value, 가치 증명)
= "이게 실제로 돈이 되냐?" 를 증명하는 단계
= 수백만 사용자가 사용해도 안전하고 안정적으로 작동하는가?
현재 AI 업계는 POC에서 POV로 넘어가는 단계임.
이 POV를 달성하기 위한 핵심 기술이 바로 가드레일임.
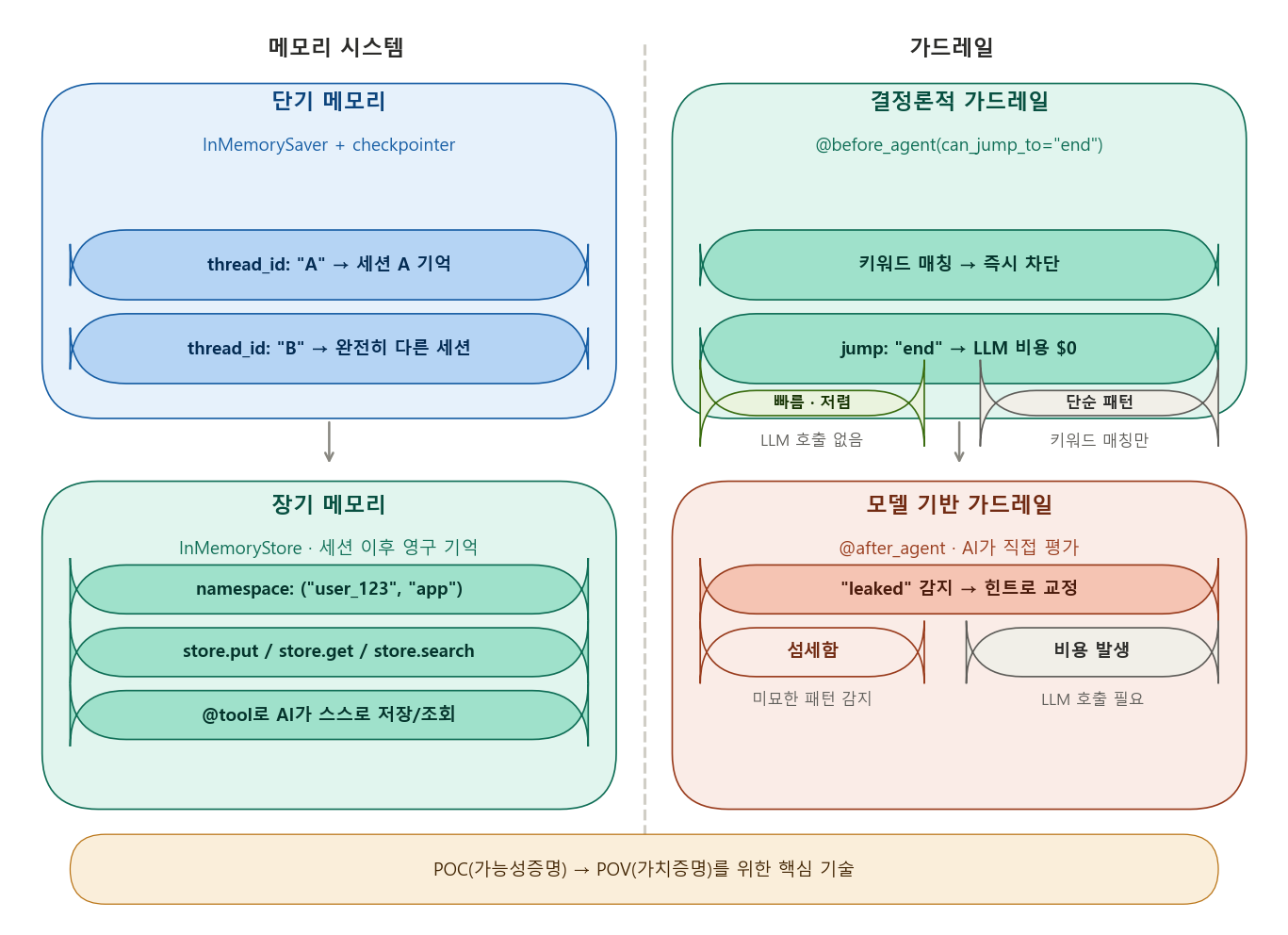
결정론적 가드레일
공항 금속 탐지기처럼 빠르고 정확함.
빠름 + 저렴 (LLM 호출 없음) + 단순 패턴에 강함
단점: 규칙에 없는 우회 방법은 감지 못함
from langchain.agents.middleware import before_agent
from langchain.schema import AIMessage, HumanMessage
FORBIDDEN = {
"cheating": ["정답 알려줘", "대신 써줘", "베껴줘", "답지"],
"distraction": ["유튜브", "게임", "롤", "넷플릭스"],
"harmful": ["욕설들...", "바보", "멍청이"]
}
RESPONSES = {
"cheating": "스스로 생각해봐야 실력이 늡니다! 힌트가 필요하면 말해줘요 😊",
"distraction": "공부 시간이에요! 딴 생각은 쉬는 시간에 해요 📚",
"harmful": "긍정적인 언어를 사용해요! 함께 공부해봐요 ✨"
}
@before_agent(can_jump_to="end")
def education_guard(state, runtime):
if not state.get("messages"):
return
last_msg = state["messages"][-1]
if not isinstance(last_msg, HumanMessage):
return
user_text = last_msg.content
for category, keywords in FORBIDDEN.items():
for keyword in keywords:
if keyword in user_text:
return {
"messages": [AIMessage(content=RESPONSES[category])],
"jump": "end" # ← 반드시 필요!
}
[작동 흐름]
입력: "이 문제 정답 알려줘"
→ "정답 알려줘" 감지 → {"jump": "end"} 반환
→ 모델 호출 건너뜀 (비용 0원!)
→ 즉각적인 응답 반환
모델 기반 가드레일
숙련된 감독관이 직접 검토함.
느림 + 비쌈 (LLM 호출 필요) + 복잡하고 미묘한 문제도 감지
예: "이 문제에서 x 값을 구하는 과정 보여줘"
→ 결정론적 가드레일: 금지어 없음 → 통과
→ 모델 기반 가드레일: "사실상 풀이 요청이다" → 차단!
from langchain.agents.middleware import after_agent
safety_ai = init_chat_model("gpt-5-nano")
@after_agent
def quality_guard(state, runtime):
if not state.get("messages"):
return
last_msg = state["messages"][-1]
if not isinstance(last_msg, AIMessage):
return
ai_answer = last_msg.content
evaluation = safety_ai.invoke([
SystemMessage("당신은 교육 품질 검사관입니다. 딱 한 단어로만 답하세요."),
HumanMessage(
f"답변이 정답이나 완전한 풀이를 직접 제공하면 'leaked', "
f"힌트나 개념만 제공하면 'safe'라고 답하세요.\n\n"
f"답변: {ai_answer}"
)
])
if "leaked" in evaluation.content.lower():
original_q = next(
(msg.content for msg in state["messages"] if isinstance(msg, HumanMessage)),
""
)
corrected = safety_ai.invoke([
SystemMessage("소크라테스식 교육법을 쓰는 AI 튜터임. 절대 정답을 직접 말하지 말 것."),
HumanMessage(f"학생 질문: {original_q}\n\n힌트와 개념만 알려줄 것.")
])
print(f"[가드레일 작동] 정답 유출 감지 → 교정됨")
last_msg.content = corrected.content
4-5. 장기 메모리 (Long-term Memory) 완전 정복
[단기 vs 장기 메모리 비유]
단기 메모리 = 현재 전화 통화
→ 통화 끊으면 사라짐
장기 메모리 = 친구와 쌓은 관계
→ 대화가 끊겨도 기억 유지
ChatGPT의 "개인 맞춤형 설정" = 장기 메모리 기능
Store 구조 이해
Store = 개인화된 메모 앱
네임스페이스 = 메모 앱의 폴더
키 = 폴더 안의 메모 파일 이름
값 = 메모 내용 (딕셔너리)
전체 구조:
Store
├── 폴더: ("user_123", "edu_assistant")
│ ├── 메모: "memory_001" → {"facts": "파이썬 선호함"}
│ └── 메모: "memory_002" → {"facts": "A 강의 완료, 90점"}
└── 폴더: ("user_456", "edu_assistant")
└── 메모: "memory_001" → {"facts": "Java 선호함"}
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace = ("user_123", "edu_assistant")
# 저장
store.put(namespace, "memory_001", {"facts": "파이썬을 선호하며 AI 에이전트에 관심이 많음"})
# 조회
item = store.get(namespace, "memory_001")
print(item.value) # {"facts": "파이썬을 선호하며 AI 에이전트에 관심이 많음"}
# 전체 조회
all_items = store.search(namespace)
에이전트에 장기 메모리 연동
from dataclasses import dataclass
from langchain.agents.middleware import wrap_model_call
@dataclass
class Context:
user_id: str
app_name: str
@wrap_model_call
def load_long_term_memory(request, handler):
namespace = (request.runtime.context.user_id, request.runtime.context.app_name)
memories = request.runtime.store.search(namespace)
if not memories:
return handler(request)
memory_lines = [f"- {mem.value['facts']}" for mem in memories if "facts" in mem.value]
memory_text = "\n".join(memory_lines)
new_system_prompt = (
f"이 사용자에 대해 알고 있는 정보:\n{memory_text}\n\n"
f"이 정보를 참고해서 개인화된 답변을 제공하세요."
)
new_request = request.override(system_prompt=new_system_prompt)
return handler(new_request)
agent = create_agent(
model,
tools=[],
middleware=[load_long_term_memory],
context_schema=Context,
store=store # ← 장기 메모리 저장소 연결 필수!
)
툴로 자동 메모리 관리
[기존 방식의 문제점]
개발자가 직접 store.put("이 사람은 파이썬 선호")를 코딩해야 함
→ 모든 사용자의 모든 대화를 개발자가 직접 저장? 불가능!
[해결책]
저장/조회 기능 자체를 툴로 만들어서
AI가 스스로 "이건 저장할 만한 정보다" 판단해서 저장하게 함
from typing import TypedDict
from uuid import uuid4
class UserMemory(TypedDict):
personal_info: str
preferences: str
@tool
def remember_user_info(memory: UserMemory, runtime) -> str:
"""사용자가 알려준 개인 정보나 선호도를 기억합니다.
사용자가 자신에 대한 정보를 말할 때 이 툴로 저장하세요."""
namespace = (runtime.context.user_id, runtime.context.app_name)
runtime.store.put(namespace, str(uuid4()), dict(memory))
return f"기억했습니다: {memory}"
@tool
def recall_user_info(runtime) -> str:
"""저장된 사용자 정보를 불러옵니다.
사용자 관련 질문에 답변하기 전에 이 툴로 기억을 확인하세요."""
namespace = (runtime.context.user_id, runtime.context.app_name)
memories = runtime.store.search(namespace)
if not memories:
return "저장된 정보가 없습니다."
all_info = []
for mem in memories:
if "personal_info" in mem.value and mem.value["personal_info"]:
all_info.append(f"개인정보: {mem.value['personal_info']}")
if "preferences" in mem.value and mem.value["preferences"]:
all_info.append(f"선호도: {mem.value['preferences']}")
return "\n".join(all_info) if all_info else "저장된 정보가 없습니다."
Step 5: RAG — 자체 데이터로 AI 강화하기
5-1. RAG란 무엇인가
[RAG를 가장 쉽게 이해하는 비유]
일반 LLM = 오픈북 없이 외운 것만으로 시험 보는 학생
→ 학습 범위 밖의 문제는 틀림
RAG 에이전트 = 교재와 노트를 옆에 두고 보는 오픈북 시험
→ 질문이 들어오면 먼저 관련 교재를 펼침 (= 검색)
→ 찾은 내용을 참고해서 답변 작성 (= 증강 + 생성)
RAG = Retrieval-Augmented Generation
Retrieval (검색): 질문 → 벡터 DB에서 관련 문서 검색
Augmented (증강): [검색된 문서] + [사용자 질문] → LLM에 함께 전달
Generation (생성): LLM이 참고 자료를 바탕으로 답변 생성
5-2. RAG 시스템 구축 4단계
원본 파일 (PDF, CSV, DB...)
↓ [1단계: Load]
Document 객체 리스트
↓ [2단계: Split]
작은 청크(Chunk) 리스트
↓ [3단계: Embed]
숫자 벡터 리스트
↓ [4단계: Store]
벡터 데이터베이스 (영구 저장)
↓ [검색: Retrieve]
질문과 유사한 청크들
↓ [답변: Generate]
최종 답변
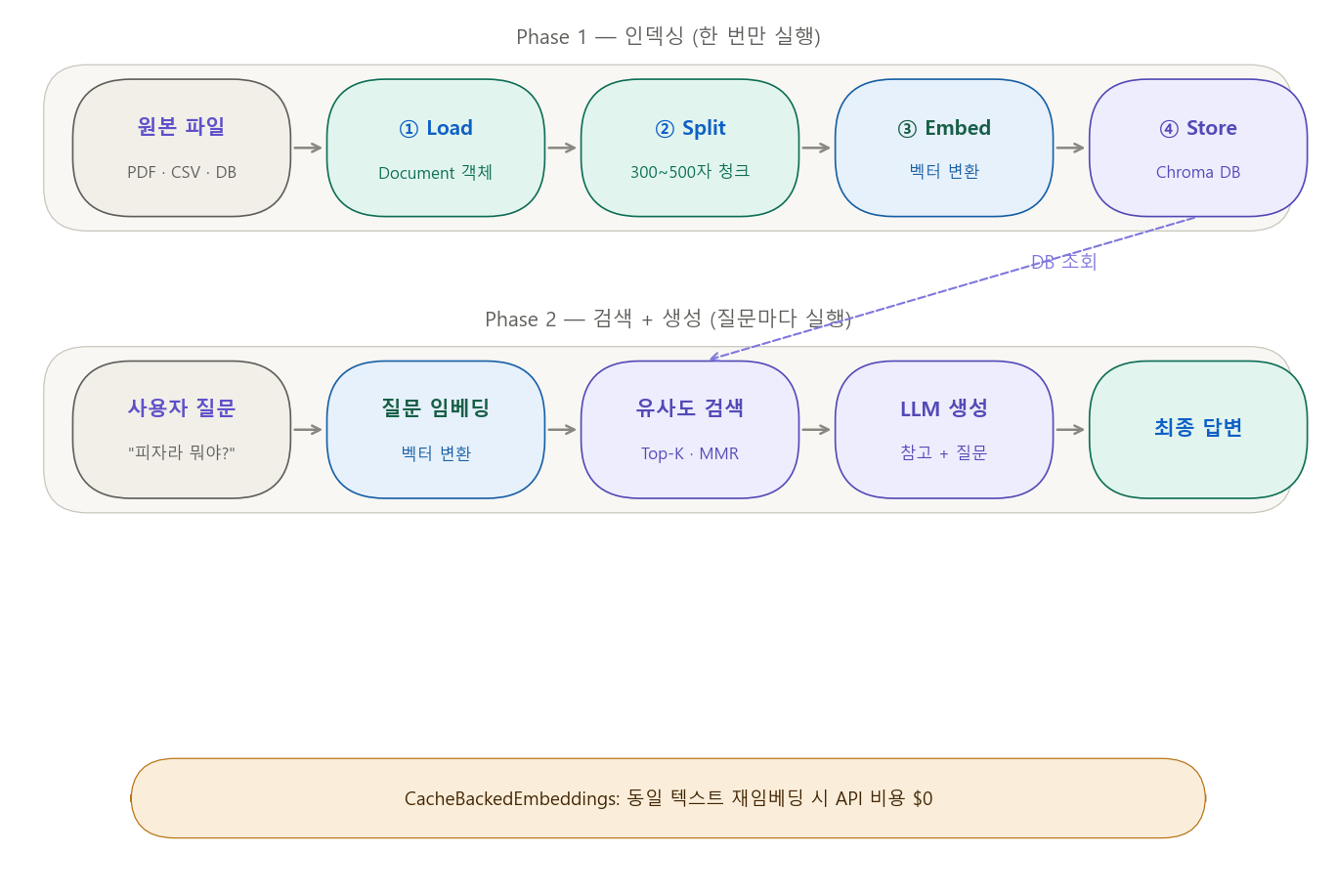
5-3. 1단계: Load — 데이터 읽어오기
from langchain_community.document_loaders import PDFPlumberLoader
loader = PDFPlumberLoader("/content/ark_portfolio.pdf")
docs = loader.load()
print(f"총 {len(docs)}개의 Document 생성됨")
print(docs[0].metadata)
# → {'source': '...', 'total_pages': 3, 'page': 0, ...}
print(docs[0].page_content[:200])
[로더 선택 가이드]
PDFPlumberLoader: C 언어 기반 → 매우 빠름 → 대량 문서 처리에 적합
PyMuPDFLoader: Python 기반 → 표 추출 지원 → 논문, 재무제표에 적합
빠르게 많이 처리? → PDFPlumberLoader
복잡한 문서 정밀 분석? → PyMuPDFLoader
5-4. 2단계: Split — 적절한 크기로 나누기
[비유]
요리할 때 재료를 써는 것과 같음.
통째로 들어온 당근 (= 전체 PDF)
→ 국에 넣기에 너무 큼 (= LLM 컨텍스트 윈도우 초과)
당근을 적당히 썰면 (= 청킹)
→ 국에 넣기 딱 좋음 (= LLM 입력에 적합)
너무 크게: 불필요한 정보 너무 많음
너무 작게: 문맥 부족
딱 적당히: 최적의 검색 정확도
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # 한 청크의 최대 글자 수
chunk_overlap=50, # 이웃 청크와 겹치는 글자 수
)
split_docs = splitter.split_documents(docs)
print(f"청킹 전: {len(docs)}개 → 청킹 후: {len(split_docs)}개")
# 3개 → 25개
[chunk_overlap이 왜 필요한가?]
청크 1: "...현재 12.26%의"
청크 2: "비중으로 포함되어 있으며..."
→ 청크 1만 보면 뒤가 잘림, 청크 2만 보면 문맥 없음
chunk_overlap=50 설정 시:
청크 2: "12%의 비중으로 포함되어 있으며..."
→ 50자 겹침으로 문맥 연결됨!
[권장 설정]
chunk_size: 300~500 (한국어 기준)
chunk_overlap: chunk_size의 10~20%
5-5. 3단계: Embed — 텍스트를 숫자로 변환하기
[임베딩이란?]
텍스트의 "의미"를 컴퓨터가 계산할 수 있는 숫자로 표현하는 것
"고양이" → [0.12, -0.34, 0.89, ...] (1536개 숫자)
"강아지" → [0.11, -0.31, 0.88, ...] (비슷한 숫자!)
"주식" → [-0.45, 0.78, -0.23, ...] (완전히 다른 숫자)
→ 유사한 의미 = 유사한 숫자 = 거리가 가까움
→ 이 거리를 계산해서 유사한 문서를 찾는 것이 벡터 검색임
from langchain_openai import OpenAIEmbeddings
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
base_embedder = OpenAIEmbeddings(model="text-embedding-3-small")
# 캐싱: 같은 텍스트 재임베딩 시 API 호출 없이 파일에서 읽음 → 비용 절감
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=base_embedder,
document_embedding_cache=LocalFileStore("./cache"),
namespace=base_embedder.model
)
| 모델 | 차원 | 1달러당 페이지 | 추천 |
|---|---|---|---|
| text-embedding-3-small | 1,536 | 62,500 | ✅ 가성비 최고 |
| text-embedding-3-large | 3,072 | 9,615 | 최고 품질 필요 시 |
| text-embedding-ada-002 | 1,536 | 12,500 | 구버전 (비권장) |
5-6. 유사도 계산 방법 3가지
코사인 유사도 — 두 벡터의 방향(각도) 비교. 텍스트 검색에 가장 많이 사용됨.
유클리드 거리 (L2) — 두 점 사이의 직선 거리. LangChain 기본값.
내적 (Dot Product) — 방향 + 크기 모두 고려.
[코사인 유사도 이해하기]
A → (3시 방향)
B → (4시 방향) → 방향 거의 같음 → 유사도 높음 (≈0.97)
A → (3시 방향)
C ← (9시 방향) → 반대 방향 → 유사도 = -1
→ 일반 텍스트 검색에는 코사인 유사도가 가장 적합함.
5-7. 4단계: Store — 영구 벡터 데이터베이스
from langchain_chroma import Chroma
vector_store = Chroma.from_documents(
documents=split_docs,
embedding=cached_embedder,
persist_directory="./chroma_db",
collection_name="ark_portfolio",
collection_metadata={"hnsw:space": "cosine"}
)
리트리버 설정 옵션
# 임계값 기반 검색
retriever = vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.4}
)
# MMR (관련있으면서 서로 다른 k개 반환 — 다양성 보장)
retriever_mmr = vector_store.as_retriever(
search_type="mmr",
search_kwargs={"k": 3}
)
[MMR 이해하기]
일반 검색: 유사도 높은 순서로 k개 → 비슷비슷한 문서 중복 가능
MMR 결과:
1. "TSLA 12.26% 최대 비중" (가장 유사)
2. "ARK 포트폴리오 전체 현황" (다른 내용)
3. "로블록스, 코인베이스 등 기타 종목" (또 다른 내용)
→ 3개가 서로 다른 관점의 정보 제공됨
5-8. 에이전틱 RAG 완전 구현
@tool
def search_ark_portfolio(query: str) -> str:
"""ARK ETF의 포트폴리오와 관련된 정보를 검색합니다.
기업 비중, 주식 보유 수량, 포트폴리오 구성을 확인할 때 사용하세요."""
retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={"k": 3}
)
docs = retriever.invoke(query)
if not docs:
return "관련 정보를 찾을 수 없습니다."
return "\n\n".join([f"[참고자료 {i+1}]\n{doc.page_content}" for i, doc in enumerate(docs)])
agent = create_agent(init_chat_model("gpt-5"), tools=[search_ark_portfolio])
result = agent.invoke({
"messages": [{"role": "user", "content": "ARK 펀드에서 테슬라 비중이 얼마야?"}]
})
print(result["messages"][-1].content)
# → "2025년 11월 26일 기준으로 테슬라(TSLA) 비중은 12.26%임."
에이전틱 RAG 내부 동작
사용자: "ARK 펀드에서 테슬라 비중이 얼마야?"
↓
[AIMessage]
tool_calls: [{"name": "search_ark_portfolio", "args": {"query": "ARK 테슬라 투자 비중 TSLA"}}]
← LLM이 스스로 작성한 검색어!
↓
[ToolMessage]
"[참고자료 1] TSLA, Tesla Inc, Shares: 12,345,678, Weight: 12.26%..."
↓
[AIMessage - 최종 답변]
"2025년 11월 26일 기준으로 테슬라(TSLA)의 투자 비중은 12.26%입니다."
Step 6: 전체 통합 — 최종 에이전트 아키텍처
지금까지 배운 모든 개념을 하나로 통합한 예시임.
import os
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain.tools import tool
from langchain.schema import AIMessage, HumanMessage, SystemMessage
from langchain.agents.middleware import before_agent, wrap_model_call, PIIMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
from langchain_chroma import Chroma
from langchain.embeddings import CacheBackedEmbeddings
from langchain_openai import OpenAIEmbeddings
from langchain.storage import LocalFileStore
from uuid import uuid4
os.environ["OPENAI_API_KEY"] = "sk-..."
@dataclass
class Context:
user_id: str
app_name: str = "edu_agent"
# 벡터 DB
vector_store = Chroma(
persist_directory="./course_db",
embedding_function=CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=OpenAIEmbeddings(model="text-embedding-3-small"),
document_embedding_cache=LocalFileStore("./cache"),
namespace="text-embedding-3-small"
),
collection_name="courses"
)
# 장기 메모리
memory_store = InMemoryStore()
# 툴 정의
@tool
def search_courses(query: str) -> str:
"""강의 정보를 검색합니다."""
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
docs = retriever.invoke(query)
return "\n\n".join([d.page_content for d in docs]) if docs else "관련 강의를 찾을 수 없습니다."
@tool
def save_student_info(info: dict, runtime) -> str:
"""학생 정보를 저장합니다."""
namespace = (runtime.context.user_id, runtime.context.app_name)
runtime.store.put(namespace, str(uuid4()), info)
return f"저장 완료: {info}"
@tool
def get_student_info(runtime) -> str:
"""학생 정보를 불러옵니다."""
namespace = (runtime.context.user_id, runtime.context.app_name)
items = runtime.store.search(namespace)
return "\n".join([str(item.value) for item in items]) if items else "저장된 정보 없음"
# 미들웨어
@before_agent(can_jump_to="end")
def anti_cheat_guard(state, runtime):
if not state.get("messages"):
return
last_msg = state["messages"][-1]
if not isinstance(last_msg, HumanMessage):
return
for keyword in ["정답 알려줘", "대신 써줘", "답 알려줘"]:
if keyword in last_msg.content:
return {
"messages": [AIMessage("스스로 생각해봐야 실력이 늡니다! 😊")],
"jump": "end"
}
@wrap_model_call
def inject_student_memory(request, handler):
namespace = (request.runtime.context.user_id, request.runtime.context.app_name)
memories = request.runtime.store.search(namespace)
if memories:
memory_text = "\n".join([f"- {item.value}" for item in memories])
new_request = request.override(system_prompt=
f"이 학생에 대해 알고 있는 정보:\n{memory_text}\n\n당신은 친절한 교육 AI 튜터입니다."
)
return handler(new_request)
return handler(request)
# 최종 에이전트
agent = create_agent(
init_chat_model("gpt-5"),
tools=[search_courses, save_student_info, get_student_info],
middleware=[
anti_cheat_guard, # 레이어 1: 부정행위 차단
PIIMiddleware(types=["email"], strategy="redact", apply_to_input=True), # 레이어 2: PII
inject_student_memory # 레이어 3: 장기 메모리
],
checkpointer=InMemorySaver(),
context_schema=Context,
store=memory_store
)
# 사용 예시
ctx = Context(user_id="student_001")
agent.invoke(
{"messages": [{"role": "user", "content": "안녕! 나는 종민이고 파이썬 배우는 중이야"}]},
config={"configurable": {"thread_id": "session_1"}},
context=ctx
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "나한테 맞는 강의 추천해줘"}]},
config={"configurable": {"thread_id": "session_2"}},
context=ctx
)
# → "종민님, 파이썬을 배우고 계시는군요! 'Python 기초부터 AI까지' 과정을 추천드립니다..."
Step 7: 자주 묻는 질문과 트러블슈팅
Q1. API 키를 OS 환경변수에 저장하는 이유가 뭔가요?
직접 코드에 넣으면:
→ GitHub에 업로드 시 키 노출 위험
→ 코드를 공유할 때마다 키 숨겨야 함
OS 환경변수에 저장하면:
→ LangChain이 자동으로 환경변수에서 읽어옴
→ 코드에 키가 노출 안 됨
→ 코드 공유 시 안전
Q2. 인보크할 때마다 매번 API 비용이 드나요?
YES. 매번 OpenAI 서버에 요청을 보내므로 비용이 발생함.
비용 최적화 방법:
1. 작은 모델 사용: gpt-5-nano (저렴) vs gpt-5 (비쌈)
2. max_tokens 제한: 불필요하게 긴 답변 방지
3. 캐싱 적용: 같은 임베딩 반복 호출 방지
4. batch 사용: 여러 요청을 한 번에 처리
5. 동적 모델 선택: 간단한 질문은 저렴한 모델로
Q3. 청크 사이즈는 얼마로 설정해야 하나요?
정답이 없음. 데이터 특성에 따라 다름.
참고 기준:
- 한국어 문서: 300~500자
- 영문 문서: 500~1000자
- 표/데이터: 더 작게 (100~200자)
- 소설/에세이: 더 크게 (500~1000자)
chunk_overlap: chunk_size의 10~20% 권장
실제 운영:
→ 여러 설정으로 테스트하고 검색 결과 품질 비교
→ LangSmith로 검색 정확도 측정
Q4. LangSmith 설정 후에도 추적이 안 돼요
원인: 환경변수 설정 전에 LangChain 모듈이 임포트됨
해결 순서:
1. 코랩 런타임 재시작
2. 패키지 설치
3. 환경변수 설정
4. 모듈 임포트
이 순서를 반드시 지켜야 함!
Q5. RAG에서 답변이 잘못 나올 때는?
원인 분석 체크리스트:
1. 청킹 문제? → chunk_size 조정 후 재시도
2. 임베딩 모델 문제? → 한국어 데이터는 Upstage 한국어 임베딩 모델 고려
3. 검색 결과 문제? → similarity_search() 결과 직접 출력해서 확인
4. 프롬프트 문제? → 시스템 프롬프트에 "제공된 참고자료만 사용하세요" 추가
5. 데이터 품질 문제? → 이미지로 된 PDF는 OCR 처리 필요
전체 요약 — 핵심 개념 30초 리뷰
[LangChain의 핵심]
에이전트 = LLM(두뇌) + Tool(팔다리)
LLM이 스스로 추론 → 필요한 툴 호출 → 결과 기반 답변
[메모리의 두 종류]
단기: checkpointer → 현재 대화 세션 기억
장기: store → 세션을 넘어 영구 기억
[미들웨어의 두 스타일]
노드 스타일(@before_agent 등): 로깅/모니터링 (읽기만)
랩 스타일(@wrap_model_call): 데이터 수정/주입 (읽기+쓰기)
[가드레일의 두 종류]
결정론적: 키워드/정규식 → 빠름, 저렴, 단순 패턴
모델 기반: AI가 평가 → 느림, 비쌈, 복잡한 패턴도 감지
[RAG의 4단계]
Load(읽기) → Split(쪼개기) → Embed(숫자화) → Store(저장)
그 후: Retrieve(검색) → Augment(증강) → Generate(답변 생성)
[컨텍스트 엔지니어링]
LLM의 작업 공간(컨텍스트 윈도우)에
딱 필요한 정보를, 적절한 형태로, 적절한 위치에 넣는 기술
LangChain 1.0 · 블룸 AI 강의 스터디 노트 · 종민
Comments