Pandas 데이터 전처리 정복: 중복 제거부터 병합, 삽입까지
이번에는 D:\python\pandas 폴더에 있는 예제 코드들을 바탕으로, 실전에서 가장 많이 쓰이는 Pandas 데이터 전처리 기법 6가지를 정리함. 데이터를 다듬고, 합치고, 수정하는 필수 스킬들이니 꼭 숙지하면 좋음.
1. 중복 데이터 제거 (drop_duplicates)
데이터를 수집하다 보면 똑같은 행이 여러 번 중복돼서 들어오는 경우가 많음. 이럴 때 drop_duplicates()를 쓰면 깔끔하게 정리할 수 있음.
import pandas as pd
# 데이터 로드
df = pd.read_csv('spambase_csv.csv')
print(f"Original Shape: {df.shape}")
# 중복된 행 개수 확인
print(f"Duplicates: {df.duplicated().sum()}")
# 중복 제거 (inplace=False가 기본값)
df_cleaned = df.drop_duplicates()
print(f"Cleaned Shape: {df_cleaned.shape}")
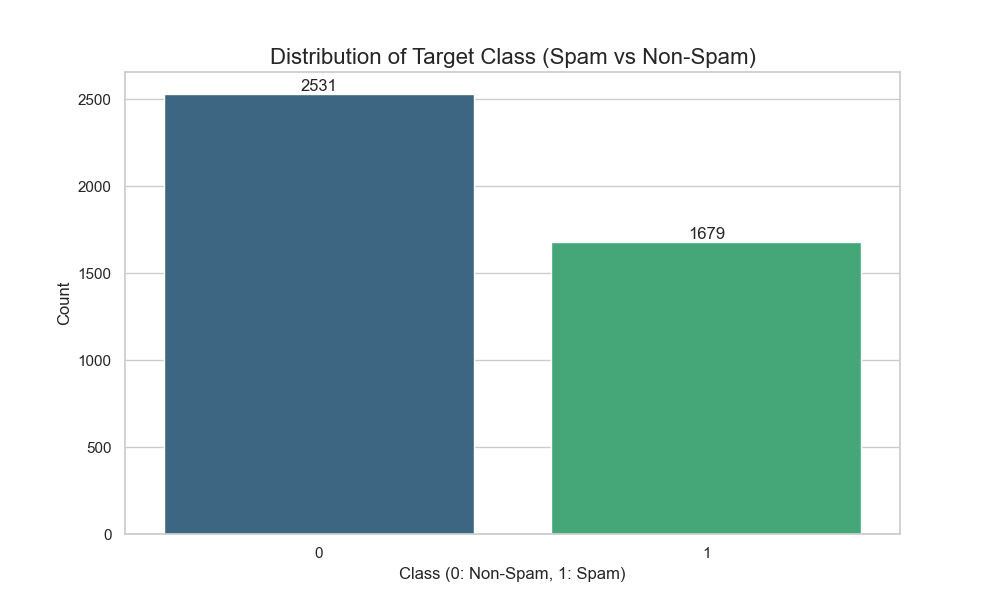
아래는 중복을 제거한 후 타겟 클래스(Class)의 분포를 시각화한 결과임.
2. 데이터 합치기 (concat)
여러 개의 데이터프레임을 하나로 합쳐야 할 때는 pd.concat()을 사용함. 위아래(행 방향)로 합칠 수도 있고, 옆으로(열 방향) 덧붙일 수도 있음.
axis=0: 위아래로 쌓기 (기본값)axis=1: 옆으로 이어 붙이기
# [실습] 데이터 쪼개기
df_part1 = df.iloc[0:100]
df_part2 = df.iloc[100:200]
# 1. 행 방향 결합 (Vertical Stack)
# ignore_index=True: 인덱스를 0부터 새로 매김
df_concat_rows = pd.concat([df_part1, df_part2], axis=0, ignore_index=True)
# 2. 열 방향 결합 (Horizontal Stack)
df_col1 = df.iloc[:10, 0:5]
df_col2 = df.iloc[:10, 5:10]
df_concat_cols = pd.concat([df_col1, df_col2], axis=1)
# 3. 키(Key) 추가해서 출처 구분하기
df_keys = pd.concat([df_part1, df_part2], keys=['Part1', 'Part2'])
3. 필요 없는 행/열 버리기 (drop, truncate)
3-1. drop 메소드
특정 라벨(인덱스나 컬럼명)을 콕 집어서 삭제할 때 사용함.
# 행 삭제 (인덱스 0, 1번 삭제)
df.drop([0, 1], inplace=True)
# 열 삭제 (컬럼명으로 삭제)
df.drop(columns=['word_freq_make', 'class'], inplace=True)
3-2. truncate 메소드
인덱스가 정렬되어 있을 때(특히 시계열 데이터), 특정 범위의 앞뒤를 잘라낼 때 유용함.
# 인덱스 10번부터 15번 사이만 남기고 나머지 잘라내기
# (슬라이싱보다 명시적인 느낌을 줌)
df_truncated = df.truncate(before=10, after=15)
4. 데이터 복사의 함정 (copy)
Pandas 데이터프레임을 변수에 할당할 때 주의해야 함. 그냥 = 기호를 쓰면 참조(Reference)가 되어, 원본 데이터가 같이 바뀌어버림.
# 1. 단순 할당 (Reference)
df_ref = df_mini
df_ref.iloc[0, 0] = 999
# -> 이러면 원본인 df_mini도 같이 999로 바뀜! (주의)
# 2. Deep Copy (안전한 복사)
df_copy = df_mini.copy(deep=True)
df_copy.iloc[0, 0] = 888
# -> 원본 df_mini는 그대로 유지됨. 안전함.
- 데이터를 가공할 때 원본을 보존하고 싶다면 반드시
.copy()를 쓰자.
5. 뽑아내고 끼워넣기 (pop, insert)
5-1. pop 메소드
컬럼을 데이터프레임에서서 뽑아서 가져옴. 동시에 데이터프레임에서는 해당 컬럼이 삭제됨. (파괴적 메서드)
# 'class' 컬럼을 뽑아서 변수에 저장하고, df에서는 삭제
target_series = df.pop('class')
5-2. insert 메소드
원하는 위치(인덱스)에 새로운 컬럼을 강제로 끼워넣음.
# 0번 컬럼 위치에 'custom_id'라는 이름으로 데이터 추가
df.insert(loc=0, column='custom_id', value=range(len(df)))
# 중복된 컬럼명도 허용하고 싶다면?
df.insert(loc=0, column='custom_id', value=..., allow_duplicates=True)
요약
오늘 다룬 Pandas 6대장 메서드:
drop_duplicates: 중복 제거concat: 데이터 블록 합체drop/truncate: 불필요한 부분 잘라내기copy: 원본 손상 방지pop: 컬럼 뽑아내기insert: 컬럼 끼워넣기
이 기능들만 자유자재로 다뤄도 데이터 전처리 속도가 훨씬 빨라질 것임.
Comments