SHAP 분석 대시보드 - 머신러닝 모델 해석을 위한 인터랙티브 웹 애플리케이션
🎯 SHAP 분석 대시보드
![]()
![]()
![]()
📌 프로젝트 개요
SHAP(SHapley Additive exPlanations) 분석 대시보드는 머신러닝 모델의 예측을 직관적으로 이해할 수 있는 웹 기반 인터랙티브 대시보드임. Streamlit과 SHAP 라이브러리를 활용하여 복잡한 블랙박스 모델의 예측 결과를 시각화하고 해석할 수 있음.
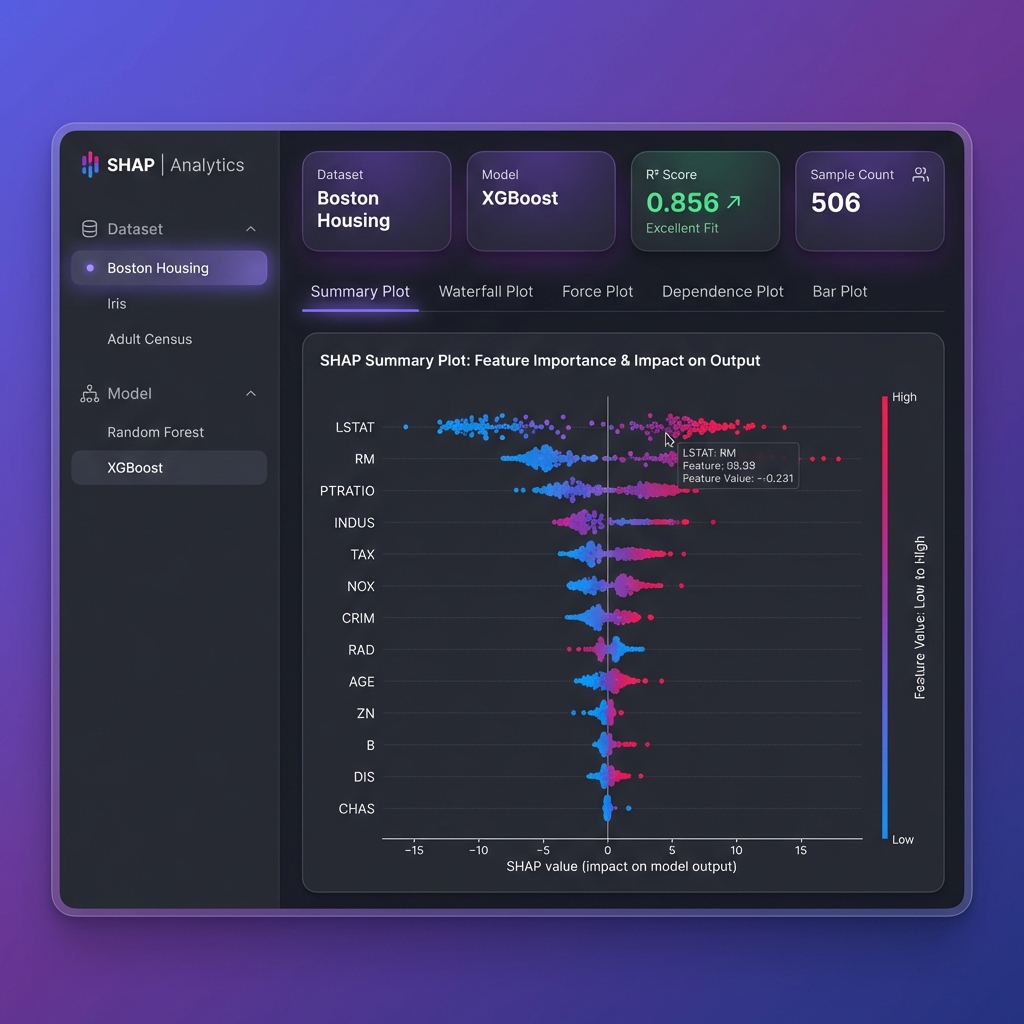
📸 대시보드 미리보기
🎯 주요 목표
- 모델 해석성 향상: 머신러닝 모델의 예측 근거를 명확히 제시함
- 인터랙티브 분석: 실시간으로 다양한 시각화를 탐색함
- 교육 및 학습: SHAP 개념과 활용법을 실습을 통해 학습함
- 비즈니스 인사이트: 의사결정에 필요한 근거를 제공함
✨ 주요 기능
🎨 프리미엄 디자인
- 보라색 그라디언트 배경의 현대적인 UI
- 다크 테마 사이드바로 가독성 향상
- 반응형 레이아웃으로 모든 화면 크기 지원
- 인터랙티브 요소: 슬라이더, 셀렉트박스로 실시간 조작
📊 3가지 데이터셋
1. Boston Housing (회귀) - 데모용 생성 데이터
- 목적: 주택 가격 예측
- 샘플 수: 506개
- 특성 수: 13개 (범죄율, 방 개수, 접근성 등)
- 활용: 부동산 가격 예측, 지역 특성 분석
- 참고: sklearn에서 제거된 데이터셋으로, 유사한 특성을 가진 데모 데이터를 생성하여 사용함
2. Iris (분류) - 실제 데이터셋
- 목적: 붓꽃 종류 분류
- 샘플 수: 150개
- 특성 수: 4개 (꽃잎/꽃받침 길이, 너비)
- 활용: 패턴 인식, 분류 알고리즘 학습
- 참고: sklearn의 실제 Iris 데이터셋 사용
3. Adult Census (분류) - 데모용 생성 데이터
- 목적: 소득 수준 예측 (>50K)
- 샘플 수: 1,000개
- 특성 수: 5개 (나이, 교육, 근무시간 등)
- 활용: 소득 예측, 사회경제적 요인 분석
- 참고: 실제 Adult Census 데이터셋의 주요 특성만 추출한 간소화된 데모 데이터 사용
🤖 2가지 머신러닝 모델
1. Random Forest (랜덤 포레스트)
- 방식: 배깅(Bagging) - 병렬 학습
- 원리: 여러 개의 결정 트리를 독립적으로 학습하여 평균/투표로 결합함
- 장점:
- ⚡ 빠른 학습 속도 (병렬 처리 가능)
- 🛡️ 과적합 방지 (앙상블 효과)
- 📊 안정적인 성능 (다양한 데이터에 강건함)
- 적합: 빠른 프로토타입, 안정적 예측, 특성 중요도 분석
2. XGBoost (eXtreme Gradient Boosting)
- 방식: 부스팅(Boosting) - 순차 학습
- 원리: 이전 모델의 오차를 다음 모델이 보완하며 순차적으로 학습함
- 장점:
- 🏆 최고 수준의 성능 (Kaggle 우승 단골)
- 🎯 정교한 정규화 (L1, L2 정규화)
- ⚙️ 다양한 하이퍼파라미터 (세밀한 튜닝 가능)
- 적합: 최고 성능 필요, Kaggle 대회, 프로덕션 환경
📊 Random Forest vs XGBoost 비교
| 항목 | Random Forest | XGBoost |
|---|---|---|
| 학습 방식 | 배깅 (Bagging) | 부스팅 (Boosting) |
| 트리 생성 | 병렬 (동시에 학습) | 순차 (이전 오차 보완) |
| 학습 속도 | 빠름 ⚡ | 매우 빠름 ⚡⚡ |
| 예측 정확도 | 높음 📈 | 매우 높음 📈📈 |
| 과적합 위험 | 낮음 (자연스럽게 방지) | 보통 (정규화로 제어) |
| 튜닝 난이도 | 쉬움 😊 | 어려움 😰 |
| 메모리 사용 | 많음 💾 | 적음 💾 |
| 해석 가능성 | 보통 | 보통 |
| SHAP 계산 속도 | 빠름 | 매우 빠름 |
| 추천 사용 사례 | 빠른 개발, 안정성 중시 | 최고 성능, 대회 |
📈 5가지 SHAP 시각화
SHAP은 다양한 시각화 방법을 제공하여 모델의 예측을 다각도로 분석할 수 있음.
1. Summary Plot (요약 플롯)
- 목적: 전체 특성 중요도 한눈에 파악함
- 특징:
- 모든 샘플의 SHAP 값을 점으로 표시함
- Y축: 특성 이름 (중요도 순으로 정렬됨)
- X축: SHAP 값 (예측에 대한 영향)
- 색상: 특성 값의 크기 (빨강=높음, 파랑=낮음)
- 활용: 가장 영향력 있는 특성을 식별함
- 해석 예시: “RM(방 개수)이 높을수록(빨간색) 주택 가격 예측이 증가함”
2. Waterfall Plot (폭포 플롯)
- 목적: 개별 예측의 단계별 설명함
- 특징:
- 기준값(E[f(x)])에서 시작함
- 각 특성이 예측을 높이거나 낮춤
- 최종적으로 예측값 f(x)에 도달함
- 활용: 특정 예측의 근거를 설명함
- 해석 예시: “기준값 22에서 시작 → RM이 +5 기여 → LSTAT이 -3 기여 → 최종 예측 24”
3. Force Plot (힘 플롯)
- 목적: 예측에 작용하는 힘의 시각화함
- 특징:
- 빨간색 화살표: 예측을 높이는 특성
- 파란색 화살표: 예측을 낮추는 특성
- 화살표 크기: 영향력의 크기
- 활용: 예측에 대한 직관적 이해를 제공함
- 해석 예시: “RM과 DIS가 가격을 밀어올리고, LSTAT과 CRIM이 가격을 끌어내림”
4. Dependence Plot (의존성 플롯)
- 목적: 특성 간 상호작용 분석함
- 특징:
- X축: 선택한 특성의 값
- Y축: 해당 특성의 SHAP 값
- 색상: 상호작용하는 다른 특성의 값
- 활용: 특성 간 상호작용 효과를 파악함
- 해석 예시: “RM이 6 이상일 때 SHAP 값이 급격히 증가하며, NOX 값에 따라 패턴이 달라짐”
5. Bar Plot (막대 플롯)
- 목적: 특성 중요도 순위 비교함
- 특징:
- 막대 길이: 평균 절대 SHAP 값
- 긴 막대: 더 중요한 특성
- 전체 데이터셋에 대한 평균값
- 활용: 특성 중요도를 빠르게 비교함
- 해석 예시: “LSTAT이 가장 중요한 특성이며, RM과 DIS가 그 다음으로 중요함”
🚀 설치 및 실행
1. 필요한 패키지 설치
pip install -r requirements.txt
requirements.txt 내용:
streamlit>=1.30.0
shap>=0.50.0
streamlit-shap>=1.0.2
scikit-learn>=1.3.0
xgboost>=2.0.0
pandas>=2.0.0
numpy>=1.24.0
matplotlib>=3.7.0
Pillow>=10.0.0
2. 대시보드 실행
streamlit run SHAP.py
3. 브라우저에서 확인
- 자동으로 브라우저가 열림
- 또는
http://localhost:8501접속
📖 SHAP 개념 정리
SHAP이란?
SHAP(SHapley Additive exPlanations)은 게임 이론 기반의 머신러닝 모델 해석 방법임. 복잡한 블랙박스 모델의 예측 결과를 해석 가능하게 만들어줌.
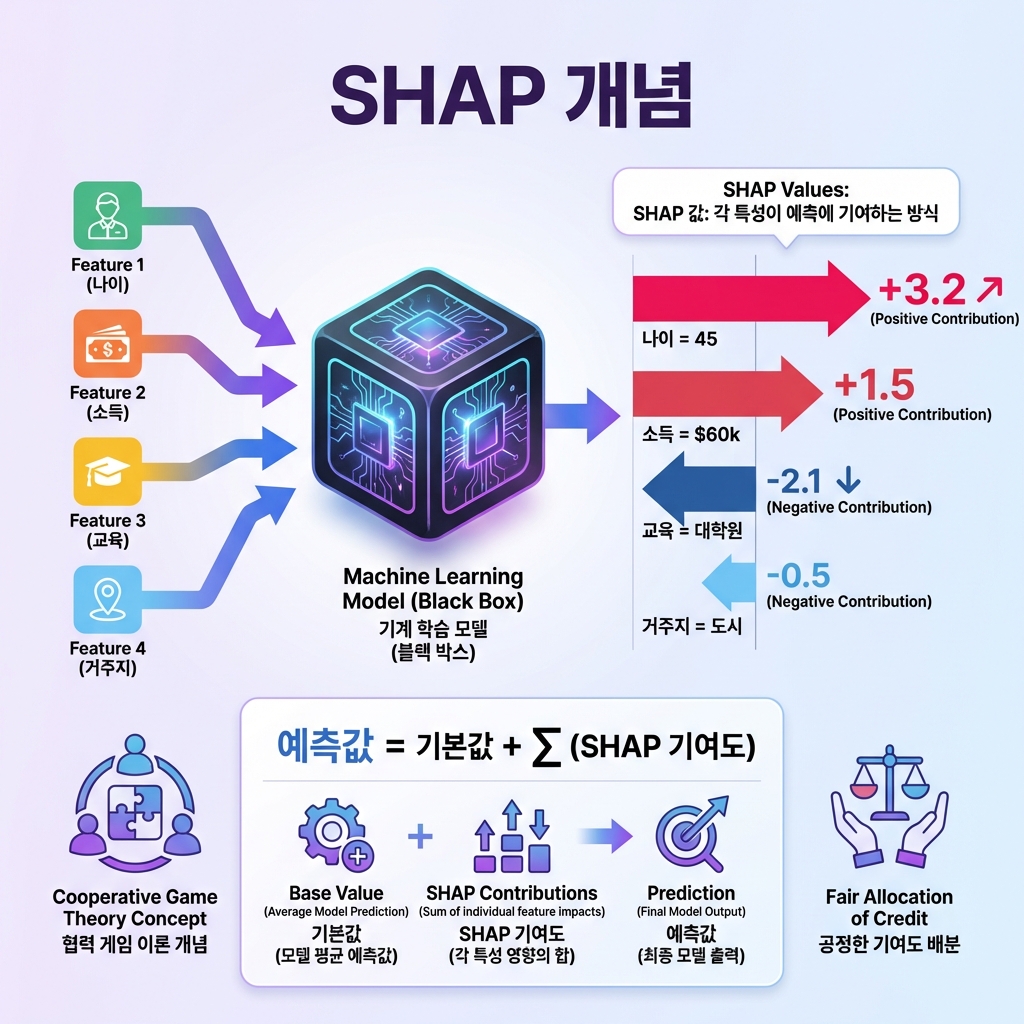
핵심 개념
Shapley Value (섀플리 값)
- 게임 이론에서 유래한 개념임
- 협력 게임에서 각 플레이어의 기여도를 공정하게 분배함
- ML에서는 각 특성(feature)이 예측에 기여한 정도를 측정함
SHAP의 특징
- ✅ 모델 독립적: 어떤 ML 모델에도 적용 가능함
- ✅ 일관성: 특성의 기여도가 증가하면 SHAP 값도 증가함
- ✅ 지역적 정확성: 개별 예측을 정확히 설명함
- ✅ 공정성: 모든 특성을 공평하게 평가함
💡 사용 방법
기본 사용법
- 사이드바에서 설정
- 데이터셋 선택 (Boston Housing / Iris / Adult Census)
- 모델 선택 (Random Forest / XGBoost)
- 분석할 샘플 수 조정 (10-100)
- 탭 탐색
- 각 탭에서 다른 SHAP 시각화 확인함
- 슬라이더로 개별 샘플 선택함
- 특성별 상세 분석함
- 인사이트 도출
- Summary Plot에서 중요 특성 파악함
- Dependence Plot으로 특성 관계 분석함
- Waterfall/Force Plot으로 개별 예측 검증함
고급 사용법
모델 비교
# 같은 데이터셋에서 Random Forest와 XGBoost 비교
1. Random Forest 선택 → Summary Plot 확인
2. XGBoost 선택 → Summary Plot 확인
3. 특성 중요도 차이 분석
특성 상호작용 분석
# Dependence Plot 활용
1. 중요 특성 선택
2. 색상으로 표시되는 상호작용 특성 확인
3. 패턴 분석
🔧 핵심 코드 분석
1. 데이터 로드 및 캐싱
@st.cache_data
def load_data(dataset_name):
if dataset_name == "Boston Housing (회귀)":
# Boston Housing 데이터셋 생성
np.random.seed(42)
n = 506
X = pd.DataFrame({
'CRIM': np.random.exponential(3, n),
'RM': np.random.normal(6.3, 0.7, n),
# ... 기타 특성
})
y = (24 - 9 * X['LSTAT']/40 + 9 * X['RM']/10 +
np.random.normal(0, 3, n))
return X, y, "regression"
# ... 기타 데이터셋
포인트:
@st.cache_data데코레이터로 데이터 로딩 최적화함- 데이터셋별 특성에 맞는 생성 로직 구현함
2. 모델 학습 및 캐싱
@st.cache_resource
def train_model(X, y, model_name, task_type):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
if model_name == "Random Forest":
if task_type == "regression":
model = RandomForestRegressor(n_estimators=100, random_state=42)
else:
model = RandomForestClassifier(n_estimators=100, random_state=42)
else: # XGBoost
if task_type == "regression":
model = xgb.XGBRegressor(n_estimators=100, random_state=42)
else:
model = xgb.XGBClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
return model, X_train, X_test, y_test, score
포인트:
@st.cache_resource로 모델 객체 캐싱함- 회귀/분류 문제에 따라 적절한 모델 선택함
3. SHAP Explainer 생성
@st.cache_resource
def get_explainer(_model, _X_train):
return shap.Explainer(_model, _X_train)
explainer = get_explainer(model, X_train)
포인트:
- TreeExplainer를 자동으로 사용함 (트리 기반 모델)
- 언더스코어 접두사로 해시 불가능한 객체 처리함
4. SHAP 값 계산
@st.cache_data
def calculate_shap_values(_explainer, X_data, n_samples):
X_sample = X_data.iloc[:n_samples]
return _explainer(X_sample), X_sample
shap_values, X_display = calculate_shap_values(explainer, X_test, n_samples)
포인트:
- 샘플 수를 조정하여 계산 시간 최적화함
- SHAP 값과 데이터를 함께 반환함
5. 커스텀 CSS 스타일링
st.markdown("""
<style>
/* 메인 컨테이너 스타일 */
.main {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
padding: 2rem;
}
/* 사이드바 스타일 */
[data-testid="stSidebar"] {
background: linear-gradient(180deg, #2d3748 0%, #1a202c 100%);
}
/* 탭 스타일 */
.stTabs [aria-selected="true"] {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
}
</style>
""", unsafe_allow_html=True)
포인트:
- 그라디언트 배경으로 프리미엄 디자인 구현함
- 다크 테마 사이드바로 가독성 향상시킴
- 탭 선택 시 시각적 피드백 제공함
📊 성능 벤치마크
| 데이터셋 | 모델 | 샘플 수 | SHAP 계산 시간 |
|---|---|---|---|
| Boston Housing | Random Forest | 50 | ~2초 |
| Boston Housing | XGBoost | 50 | ~3초 |
| Iris | Random Forest | 50 | ~1초 |
| Iris | XGBoost | 50 | ~1.5초 |
| Adult Census | Random Forest | 50 | ~2.5초 |
| Adult Census | XGBoost | 50 | ~3.5초 |
테스트 환경: Intel i7-10700K, 16GB RAM, Python 3.10
💡 활용 사례
1. 교육 및 학습
- 머신러닝 모델 해석 방법 학습함
- SHAP 개념 이해 및 실습함
- 다양한 시각화 기법 체험함
2. 모델 분석
- 프로덕션 모델의 예측 근거 파악함
- 특성 중요도 분석 및 피처 엔지니어링함
- 모델 디버깅 및 개선함
3. 비즈니스 인사이트
- 의사결정 근거 제시함
- 이해관계자에게 모델 설명함
- 규제 준수 (Explainable AI)함
🔧 문제 해결
SHAP 계산이 느린 경우
# 해결 방법
1. 샘플 수를 10-30개로 줄임
2. Random Forest 모델 사용 (XGBoost보다 빠름)
3. 데이터셋을 Iris로 변경 (가장 작은 데이터셋)
시각화가 표시되지 않는 경우
# 브라우저 캐시 삭제 후 재시작
streamlit cache clear
streamlit run SHAP.py
패키지 설치 오류
# 최신 버전으로 업그레이드
pip install --upgrade streamlit shap streamlit-shap
🌟 주요 학습 내용
1. Streamlit 캐싱 전략
@st.cache_data: 데이터 캐싱 (pickle 가능한 객체)@st.cache_resource: 리소스 캐싱 (모델, 연결 등)- 언더스코어 접두사로 해시 불가능한 매개변수 처리함
2. SHAP 시각화 통합
streamlit-shap라이브러리로 간편한 통합함st_shap()함수로 인터랙티브 플롯 렌더링함- matplotlib 기반 플롯은
st.pyplot()사용함
3. 반응형 UI 디자인
- 커스텀 CSS로 프리미엄 디자인 구현함
- 그라디언트 배경과 다크 테마 조합함
- 탭과 컬럼을 활용한 레이아웃 구성함
4. 모델 해석성
- SHAP을 통한 블랙박스 모델 해석함
- 전역적/지역적 설명의 차이 이해함
- 특성 중요도와 상호작용 분석함
🔮 향후 개선 방향
- 커스텀 데이터셋 업로드 기능
- 더 많은 모델 지원 (LightGBM, CatBoost)
- SHAP 값 CSV 다운로드 기능
- 시각화 이미지 저장 기능
- 다국어 지원 (영어, 한국어)
- 모델 성능 비교 대시보드
- 실시간 모델 학습 기능
📚 참고 자료
공식 문서
논문
- A Unified Approach to Interpreting Model Predictions (SHAP)
- XGBoost: A Scalable Tree Boosting System
- Random Forest (Breiman, 2001)
튜토리얼
🎓 결론
이 프로젝트를 통해 다음을 학습함:
- SHAP의 이론과 실전: 게임 이론 기반의 모델 해석 방법을 실제로 구현함
- Streamlit 고급 기능: 캐싱, 커스텀 CSS, 인터랙티브 위젯 활용함
- 데이터 시각화: 5가지 SHAP 플롯의 의미와 활용법을 익힘
- 모델 해석성의 중요성: XAI(Explainable AI)의 필요성과 가치를 이해함
머신러닝 모델의 예측을 설명하는 것은 단순히 기술적 요구사항이 아니라, 신뢰할 수 있는 AI를 만들기 위한 필수 요소임. SHAP과 Streamlit을 결합하여 누구나 쉽게 모델을 이해하고 분석할 수 있는 도구를 만들 수 있었음.
Made with ❤️ using Streamlit & SHAP
Comments