[Kaggle] 과소적합과 과대적합 (Underfitting and Overfitting) 번역 및 정리
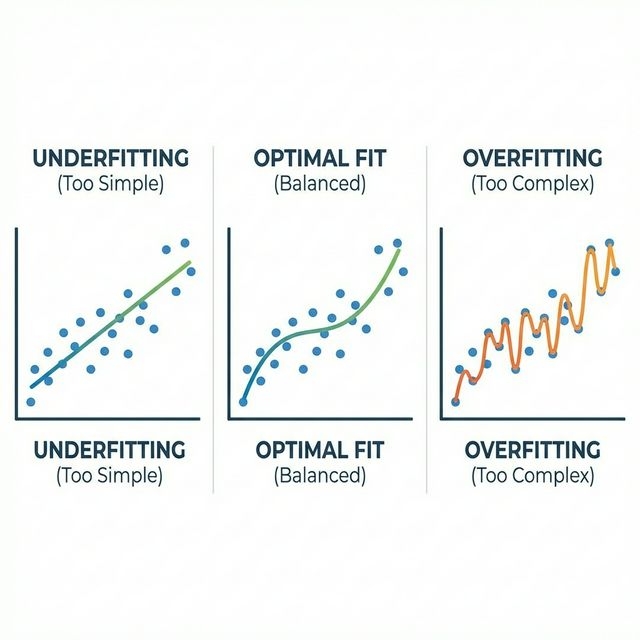
📌 과소적합(Underfitting)과 과대적합(Overfitting)
이전 튜토리얼에서 모델의 정확도를 객관적으로 평가하기 위해 검증 데이터(Validation Data)를 나누고, 평균 절대 오차(MAE)를 계산하는 방법을 배웠음. 모델의 성능을 체계적으로 파악할 수 있게 되었으니, 이제 다양한 설정을 변경하며 모델을 더 완벽하게 미세 조정(Fine-tuning) 하는 방법을 알아봄.
이 단계를 마치면 머신러닝에서 가장 중요한 개념 중 하나인 과대적합(Overfitting)과 과소적합(Underfitting)을 명확히 이해하고, 이를 통제해 모델 성능을 끌어올릴 수 있음.
1️⃣ 예측 모델의 깊이와 복잡도
머신러닝 알고리즘에는 모델의 구조를 결정짓는 여러 가지 설정값(옵션)이 있음. 우리가 실습 중인 의사결정나무(Decision Tree)의 경우, 트리의 깊이(Depth)를 변경할 수 있음.
트리의 깊이는 최종 예측(리프 노드)에 도달할 때까지 데이터가 얼마나 많이 쪼개지느냐를 의미함. 더 많이 쪼개질수록 예측의 가짓수가 늘어남.
2️⃣ 과대적합 (Overfitting) 이란?
트리가 매우 깊어지면 여러 번의 분할을 거치면서 데이터가 수많은 그룹으로 잘게 나뉨. 결과적으로 맨 끝에 있는 각각의 리프 노드(최종 예측 결과)에는 아주 적은 수의 집들만 남게 됨.
- 문제점: 이렇게 적은 데이터만으로 각 그룹의 특성을 정의해 버리면, 실제 본질적인 가격 변동 패턴보다는 특이한 관측치(이상치나 노이즈)에 의존하여 예측하게 됨.
- 결과: “초록색 문이 있는 모서리 집은 무조건 비싸다”와 같은 우연한 패턴을 맹신하게 됨.
- 현상: 모델이 훈련 데이터(Training Data)에는 너무나도 완벽하게 일치하여 오차가 거의 0에 가깝지만, 아예 새로운 데이터(Validation Data)를 넣었을 때는 예측이 엉망진창이 되는 현상을 바로 과대적합(Overfitting)이라고 함.
3️⃣ 과소적합 (Underfitting) 이란?
반대로 트리를 너무 적게 분할하면(깊이가 아주 얕다면), 집약된 아주 큰 두세 개의 범주로만 집들을 나눈 채 예측을 수행하게 됨.
- 문제점: 데이터의 세부적인 특징(방 개수, 넓이 등)을 충분히 반영하지 못한 채 두루뭉술한 평균값으로 예측해버림.
- 결과: 패턴 자체를 제대로 포착하지 못했기 때문에 검증 데이터뿐만 아니라, 스스로 학습했던 훈련 데이터에서조차 오차가 크게 발생함.
- 현상: 이처럼 모델이 너무 단순해서 데이터의 필수적인 변수 관계망조차 파악하지 못하는 현상을 과소적합(Underfitting)이라고 함.
⚖️ 최적의 지점 (The Sweet Spot) 찾기
모델을 구축할 때 우리의 궁극적인 목표는 항상 “새롭게 들어오는 검증 데이터(Validation Data)에 대한 예측 오차를 최소화” 하는 것임.
일반적으로 트리 깊이(모델 복잡성)에 따른 오차 그래프는 U자 형태를 띰.
- 처음엔 깊이가 얕아 과소적합 상태라 오차가 큼.
- 깊이가 깊어지면서 오차가 점점 줄어듦.
- 하지만 어느 지점(Sweet Spot)을 넘어가면 오히려 훈련 데이터의 잡음(Noise)까지 학습하기 시작하며 과대적합이 발생함. 이때부터 검증 데이터의 오차는 다시 폭발적으로 치솟게 됨.
머신러닝 엔지니어의 핵심 역할 중 하나는, 바로 검증 오차가 최소가 되는 이 최적의 지점(Sweet Spot)을 찾아내는 것임.
💻 어떻게 최적화할 수 있을까? (예시 코드)
Scikit-learn의 DecisionTreeRegressor에는 최대 리프 노드의 개수를 제한하는 max_leaf_nodes라는 인자가 있음. 이 값을 조절하여 트리의 복잡도를 제어함.
다양한 값을 테스트해 보면서 최적의 결과(가장 낮은 MAE)를 내는 노드 개수를 찾는 구조임.
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
# max_leaf_nodes 수치에 따른 평균절대오차(MAE)를 계산해 주는 함수
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
# 실험할 여러 노드 개수 후보군 설정
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
위의 결과에서 MAE가 가장 낮게 나온 max_leaf_nodes 수치가 바로 현재 모델과 데이터의 “Sweet Spot”임. 해당 매개변수를 적용하여 우리 모델을 새롭게 훈련시키면 성능이 극대화된 최종 모델을 얻게 됨.
📋 핵심 요약
- 과대적합(Overfitting): 모델이 미래에 나타날 패턴보다는 훈련 데이터 특유의 노이즈와 특이점까지 억지로 외워버린 상태. 결과적으로 새로운 데이터(검증용)에 적용했을 때 처참한 성능을 보임.
- 과소적합(Underfitting): 모델이 너무 단순해서 훈련 데이터 속에 숨겨진 명확한 패턴조차 제대로 학습하지 못한 상태. 훈련/검증 데이터 모두에서 형편없는 오차만 기록함.
- 우리는 별도의 자체 검증 데이터(Validation Data)를 사용하여, 과소적합과 과대적합 사이의 가장 균형 잡힌 최적의 복잡도(Sweet Spot)를 찾아야만 모델의 정확도를 보장할 수 있음.
Comments