[Kaggle] 모델이 작동하는 방식 (How Models Work) 번역 및 정리
📌 모델이 작동하는 방식 (How Models Work)
머신러닝 모델이 어떻게 작동하고 어떻게 사용되는지에 대한 개요부터 시작함. 통계 모델링이나 머신러닝을 이전에 접해본 적이 있다면 이 내용이 매우 기초적으로 느껴질 수 있음. 걱정하지 않아도 됨. 곧 강력한 모델을 구축하는 단계로 나아갈 것임.
이 과정에서는 다음과 같은 가상의 시나리오를 바탕으로 모델을 구축하게 됨:
“당신의 사촌은 부동산 투기로 수백만 달러를 벌었음. 그는 당신의 데이터 과학에 대한 관심을 알고 사업 파트너가 될 것을 제안함. 사촌이 자금을 공급하고, 당신은 다양한 주택의 가치가 얼마인지 예측하는 모델을 제공하기로 함.”
당신은 사촌에게 과거에 부동산 가치를 어떻게 예측했는지 물었고, 그는 단순히 ‘직관’이라고 대답함. 하지만 더 자세히 물어보니, 그는 과거에 보았던 집들에서 가격 패턴을 파악해냈고, 그 패턴을 사용하여 고려 중인 새 주택의 가격을 예측하고 있었음.
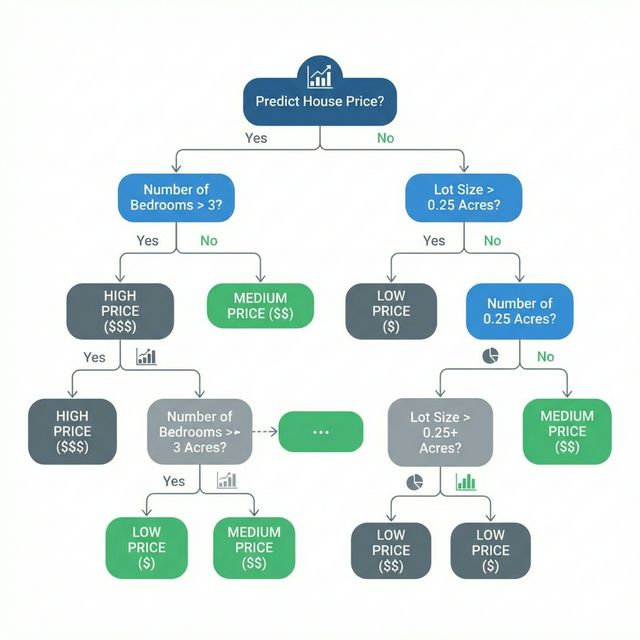
머신러닝도 똑같은 방식으로 작동함. 우리는 의사 결정 나무(Decision Tree)라는 모델부터 시작할 것임. 더 정확한 예측을 제공하는 화려한 모델들도 많지만, 의사 결정 나무는 이해하기 쉽고 데이터 과학에서 가장 뛰어난 모델들의 기초가 되는 핵심 구성 요소임.
1️⃣ 단순한 의사 결정 나무 (Basic Decision Tree)
단순함을 위해 가장 간단한 형태의 의사 결정 나무로 시작해 봄.
이 모델은 집을 단 두 개의 범주로만 나눔. 고려 중인 모든 주택의 예상 가격은 동일한 범주에 속한 주택들의 과거 평균 가격이 됨.
우리는 데이터를 사용하여 집을 두 그룹으로 나누는 기준을 정하고, 각 그룹의 예상 가격을 결정함. 데이터에서 패턴을 포착하는 이 단계를 모델을 피팅(Fitting) 한다 하거나 훈련(Training) 시킨다고 함. 모델을 피팅하는 데 사용되는 데이터를 훈련 데이터(Training Data)라고 부름.
모델이 어떻게 피팅되는지에 대한 세부 사항(예: 데이터를 나누는 방법)은 충분히 복잡하므로 나중에 다루도록 함. 모델이 피팅된 후에는 이를 새로운 데이터에 적용하여 추가적인 주택의 가격을 예측(Predict) 할 수 있음.
2️⃣ 의사 결정 나무의 개선 (Improving the Decision Tree)
부동산 훈련 데이터를 피팅할 때, 어떤 기준이 모델의 결과로 나타날 가능성이 높을까?
예를 들어 ‘침실 개수’를 기준으로 나눈 의사 결정 나무가 더 타당할 수 있음. 침실이 많은 집이 침실이 적은 집보다 더 높은 가격에 팔리는 현실을 반영하고 있기 때문임. 하지만 이 단순한 모델의 가장 큰 단점은 욕실 개수, 대지 크기, 위치 등 주택 가격에 영향을 미치는 대부분의 요소를 반영하지 못한다는 점임.
더 많은 “분할(splits)”을 가진 나무를 사용하면 더 많은 요소를 반영할 수 있음. 이를 더 “깊은(deeper)” 나무라고 부름.
각 주택의 특성에 해당하는 트리 경로를 따라 추적함으로써 어떤 주택의 가격이든 예측할 수 있음. 주택의 예상 가격은 나무의 맨 아래에 표시됨. 예측이 이루어지는 이 맨 아래 지점을 리프(Leaf, 잎)라고 부름.
리프에서의 분할 기준과 값은 데이터에 의해 결정되므로, 다음 단계에서는 직접 작업하게 될 데이터를 살펴보게 됨.
🚀 다음 단계: 데이터 살펴보기 (Examine Your Data)
더 구체적인 단계로 넘어가서 부동산 데이터를 직접 조사하며 머신러닝의 실전 감각을 익혀볼 예정임.
Comments