[ML] 머신러닝 기초 — 지도학습 & 단변량 선형회귀분석
1. 머신러닝(Machine Learning)이란?
정의
“데이터로부터 스스로 학습하여 예측/판단하는 알고리즘을 만드는 방법론”
기존 프로그래밍과의 차이:
| 구분 | 전통적 프로그래밍 | 머신러닝 |
|---|---|---|
| 흐름 | 데이터 + 규칙(코드) → 정답 | 데이터 + 정답(레이블) → 규칙(모델) |
| 규칙 주체 | 개발자가 직접 작성 | 알고리즘이 데이터에서 추출 |
| 적합한 문제 | 규칙이 명확한 경우 | 규칙이 복잡하거나 정의하기 어려운 경우 |
머신러닝의 3가지 분류
| 분류 | 설명 | 예시 |
|---|---|---|
| 지도학습 (Supervised) | 레이블 있는 데이터로 학습 | 집값 예측, 스팸 분류 |
| 비지도학습 (Unsupervised) | 레이블 없는 데이터에서 패턴 발견 | 고객 군집화, 이상 탐지 |
| 강화학습 (Reinforcement) | 보상(reward) 기반으로 행동 최적화 | 게임 AI, 로봇 제어 |
2. 지도학습(Supervised Learning)
개념
입력변수 X와 정답 y가 쌍(pair) 으로 주어진 데이터로 모델을 학습시키는 방법.
학습 후 새로운 X가 입력되면 y를 예측한다.
학습 단계
훈련 데이터 (X, y) → 학습 알고리즘 → 학습된 모델 f(X)
예측 단계
새로운 입력 X → 학습된 모델 f(X) → 예측값 ŷ
지도학습의 두 갈래
| 종류 | 출력값 | 예시 |
|---|---|---|
| 회귀 (Regression) | 연속형 숫자 | 집값, 주가, 온도, 판매량 |
| 분류 (Classification) | 범주(클래스) | 스팸/정상, 암/정상, 다중 분류 |
3. 단변량 선형회귀분석(Simple Linear Regression)
개념
독립변수(X) 1개로 종속변수(y)를 예측하는 가장 기본적인 회귀 모델.
데이터를 가장 잘 설명하는 직선을 찾는 것이 목표.
회귀식
모집단 (이론)
y = β₀ + β₁x + ε
표본 추정 (실제 사용)
ŷ = b₀ + b₁x
| 기호 | 의미 |
|---|---|
β₀, b₀ |
절편 (intercept) — x=0일 때 y값 |
β₁, b₁ |
기울기 (slope) — x가 1 증가할 때 y 변화량 |
ε |
오차항 (error term) — 설명되지 않는 변동 |
ŷ |
예측값 (y-hat) |
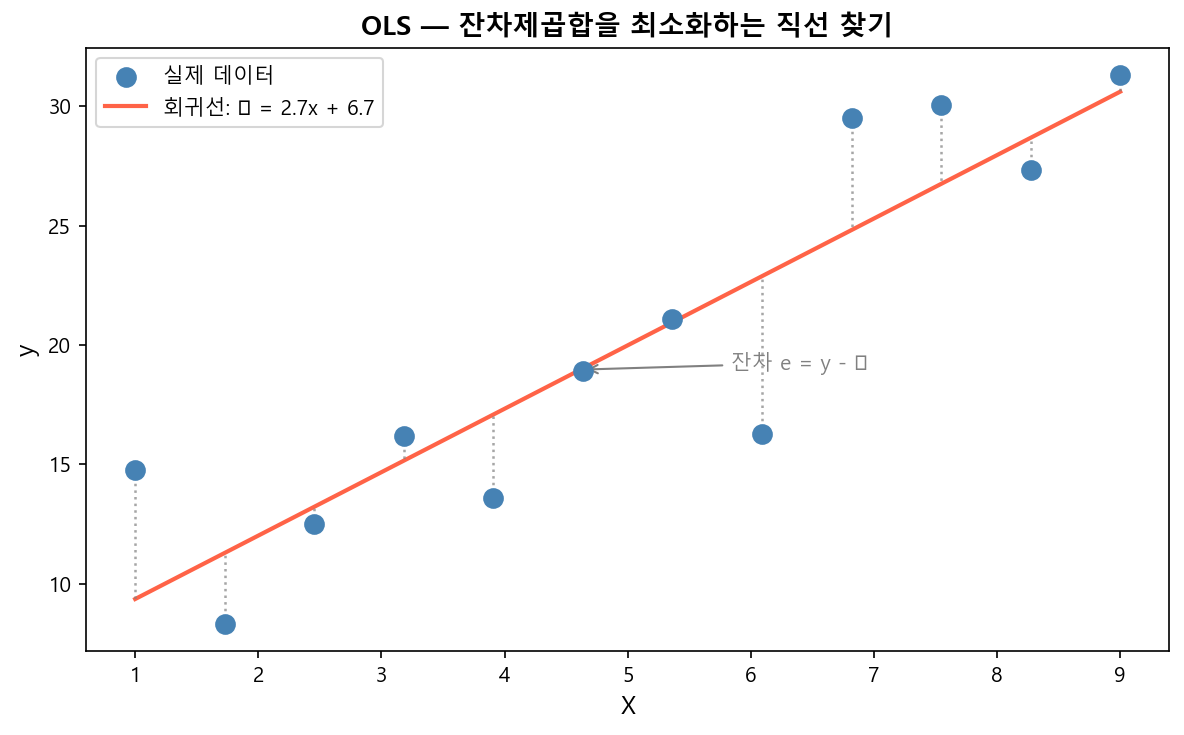
4. OLS (최소제곱법, Ordinary Least Squares)
β₀, β₁을 추정하는 방법. 잔차(residual)의 제곱합(RSS)을 최소화하는 계수를 수학적으로 구한다.
잔차(Residual)
eᵢ = yᵢ - ŷᵢ (실제값 - 예측값)
기울기 추정
b₁ = Σ(xᵢ - x̄)(yᵢ - ȳ) / Σ(xᵢ - x̄)²
= Cov(X, y) / Var(X)
절편 추정
b₀ = ȳ - b₁ · x̄
회귀선은 반드시 표본 평균점 (x̄, ȳ) 를 통과한다.
5. 성능 평가 지표
MSE (Mean Squared Error, 평균제곱오차)
MSE = (1/n) Σ(yᵢ - ŷᵢ)²
- 낮을수록 좋음
- 단위: y의 단위² → 해석이 어색
RMSE (Root MSE, 평균제곱근오차)
RMSE = √MSE
- MSE에 루트를 취해 y와 같은 단위로 해석 가능
- “평균적으로 예측이 ±RMSE만큼 빗나간다”
R² (결정계수, Coefficient of Determination)
R² = 1 - RSS/TSS
= 1 - Σ(yᵢ - ŷᵢ)² / Σ(yᵢ - ȳ)²
- 범위: 0 ~ 1 (높을수록 좋음)
- “모델이 y의 분산을 몇 % 설명하는가”
- R² = 0.95 → 95% 설명
| RSS | TSS |
|---|---|
| 잔차제곱합 (설명 못한 변동) | 전체제곱합 (전체 변동) |
6. 전체 실습 코드 (Line-by-Line)
STEP 1 — 라이브러리 임포트 및 데이터 준비
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 예시: 공부 시간(X) → 시험 점수(y) 데이터 생성
np.random.seed(42) # 재현성을 위한 시드 고정
X = np.random.uniform(1, 10, 50).reshape(-1, 1) # (50,1) shape — sklearn 요구사항
y = 5 * X.flatten() + 20 + np.random.normal(0, 8, 50) # y = 5x + 20 + 노이즈
reshape(-1, 1)이유: sklearn의 LinearRegression은 X를 2D 배열(n_samples, n_features)형태로 요구.
-1은 “자동으로 행 개수 계산”을 의미.
np.random.normal(0, 8, 50): 평균=0, 표준편차=8인 정규분포 잡음 → 실제 데이터의 불완전성 시뮬레이션.
STEP 2 — 데이터 분할 (훈련 / 테스트)
# 80% 훈련 / 20% 테스트로 분리 (과적합 방지를 위해 필수)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2, # 전체의 20%를 테스트셋으로
random_state=42 # 재현 가능한 분할
)
print(f"훈련셋: {X_train.shape[0]}개, 테스트셋: {X_test.shape[0]}개")
# 출력: 훈련셋: 40개, 테스트셋: 10개
테스트셋은 모델이 학습 중에 절대 보지 않은 데이터.
훈련셋으로만 학습하고, 테스트셋으로 평가해야 일반화 성능을 신뢰할 수 있다.
STEP 3 — 모델 학습 (OLS)
# LinearRegression은 내부적으로 OLS로 β₀, β₁을 계산
model = LinearRegression() # 모델 객체 생성
model.fit(X_train, y_train) # 훈련 데이터로 b₀, b₁ 추정
# 추정된 계수 확인
print(f"절편(b₀): {model.intercept_:.4f}") # ≈ 20
print(f"기울기(b₁): {model.coef_[0]:.4f}") # ≈ 5
print(f"회귀식: y = {model.coef_[0]:.2f}x + {model.intercept_:.2f}")
model.fit()내부 동작:
b₁ = Cov(X, y) / Var(X), b₀ = ȳ - b₁·x̄ 를 행렬 연산으로 계산.
STEP 4 — 예측 및 성능 평가
# 테스트셋에 대한 예측값 생성
y_pred = model.predict(X_test) # ŷ = b₀ + b₁ * X_test
# 성능 지표 계산
mse = mean_squared_error(y_test, y_pred) # MSE = (1/n)Σ(y - ŷ)²
rmse = np.sqrt(mse) # RMSE = √MSE (y와 같은 단위)
r2 = r2_score(y_test, y_pred) # R² = 1 - RSS/TSS
print(f"MSE: {mse:.4f}")
print(f"RMSE: {rmse:.4f}") # "평균적으로 ±RMSE만큼 오차"
print(f"R²: {r2:.4f}") # 1에 가까울수록 좋음
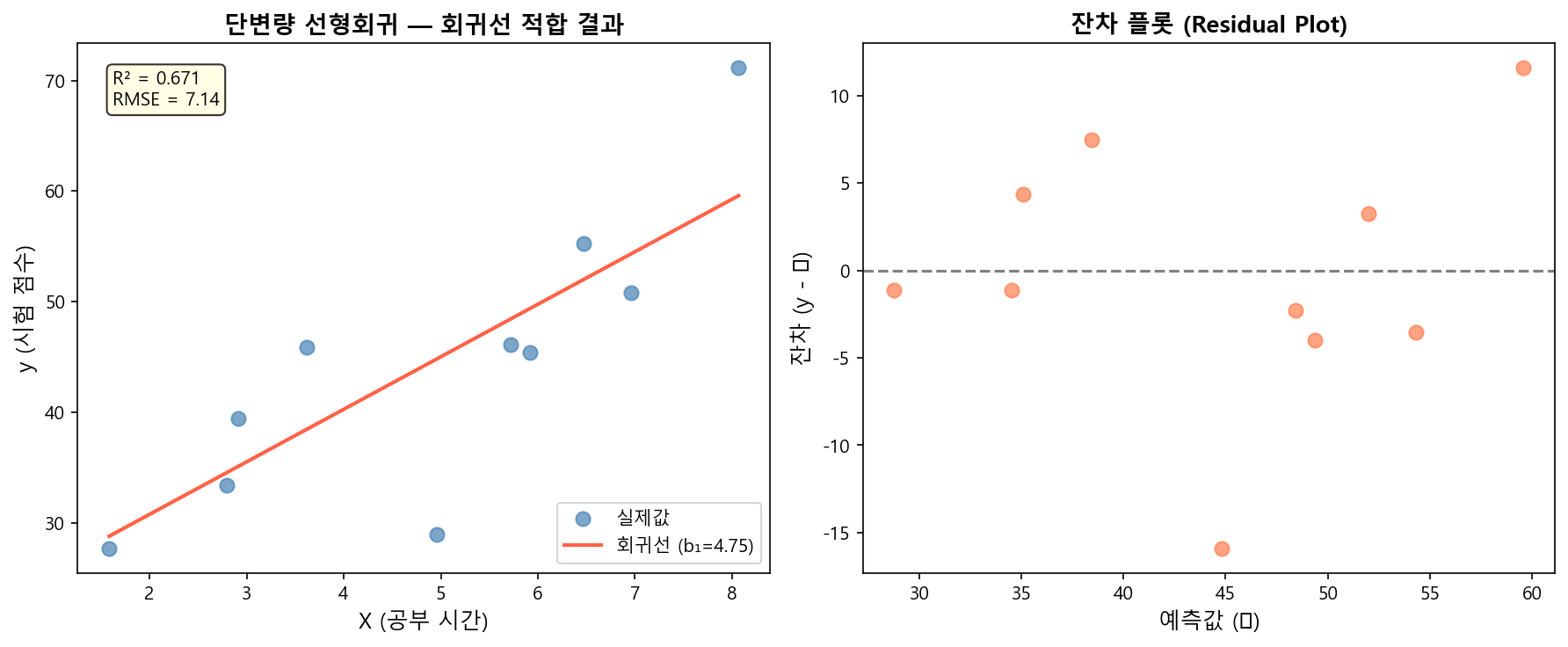
STEP 5 — 시각화
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 왼쪽: 산점도 + 회귀선
axes[0].scatter(X_test, y_test, color='steelblue', label='실제값', alpha=0.7)
axes[0].plot(X_test, y_pred, color='tomato', linewidth=2, label='회귀선')
axes[0].set_xlabel('X (공부 시간)')
axes[0].set_ylabel('y (시험 점수)')
axes[0].set_title('회귀선 적합 결과')
axes[0].legend()
# 오른쪽: 잔차 플롯 (패턴이 없어야 좋은 모델)
residuals = y_test - y_pred
axes[1].scatter(y_pred, residuals, color='coral', alpha=0.7)
axes[1].axhline(0, color='gray', linestyle='--') # y=0 기준선
axes[1].set_xlabel('예측값 (ŷ)')
axes[1].set_ylabel('잔차 (y - ŷ)')
axes[1].set_title('잔차 플롯 (Residual Plot)')
plt.tight_layout()
plt.show()
잔차 플롯(Residual Plot) 해석:
- 잔차가 y=0 주변에 무작위 분포 → 선형 가정 성립 ✅
- 패턴(U자, 깔때기형)이 보이면 → 비선형 모델 검토 또는 변수 추가 필요 ⚠️
STEP 6 — 예외 처리 (try / except) 추가
실습 코드도 실제로는 입력 데이터 문제(결측치, shape 오류, 빈 데이터) 때문에 자주 실패할 수 있다.
아래처럼 try / except를 넣어두면 디버깅과 운영 안정성이 높아진다.
from sklearn.exceptions import NotFittedError
try:
# 1) 데이터 기본 검증
if X.size == 0 or y.size == 0:
raise ValueError("X 또는 y가 비어 있습니다.")
if np.isnan(X).any() or np.isnan(y).any():
raise ValueError("결측치(NaN)가 포함되어 있습니다. 전처리를 먼저 수행하세요.")
# 2) 모델 학습 및 예측
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
except ValueError as e:
print(f"[입력 데이터 오류] {e}")
except NotFittedError as e:
print(f"[모델 상태 오류] 학습(fit) 후 예측(predict)해야 합니다: {e}")
except Exception as e:
print(f"[기타 예외] 예상치 못한 오류가 발생했습니다: {e}")
자주 보는 예외 유형:
ValueError: shape 불일치, NaN 포함, 빈 데이터 등 입력값 문제NotFittedError:fit()전에predict()호출Exception: 위에서 잡지 못한 기타 예외(최후 방어선)
7. 핵심 수식 정리
| 항목 | 수식 | 설명 |
|---|---|---|
| 회귀식 | ŷ = b₀ + b₁x |
예측값 |
| 기울기 | b₁ = Cov(X,y) / Var(X) |
OLS 추정 |
| 절편 | b₀ = ȳ - b₁x̄ |
평균점 통과 보장 |
| 잔차 | eᵢ = yᵢ - ŷᵢ |
실제 - 예측 |
| MSE | (1/n) Σ(yᵢ - ŷᵢ)² |
평균제곱오차 |
| RMSE | √MSE |
y와 같은 단위 |
| R² | 1 - RSS/TSS |
설명력 (0~1) |
핵심 흐름: 데이터 → OLS로 b₀·b₁ 추정 → ŷ 예측 → R²·잔차 플롯으로 진단
8. 전체 프로세스 요약
① 데이터 수집
↓
② EDA (탐색적 분석) — 산점도, 상관계수 확인
↓
③ train / test 분할 (일반적으로 8:2)
↓
④ 모델 학습 — OLS로 b₀, b₁ 추정
↓
⑤ 예측 — ŷ = b₀ + b₁x
↓
⑥ 성능 평가 — MSE, RMSE, R²
↓
⑦ 잔차 분석 — 등분산성, 정규성, 독립성 확인
↓
⑧ 해석 및 보고
9. 단변량 → 다변량 확장
단변량 선형회귀의 자연스러운 다음 단계는 다변량(다중) 선형회귀:
ŷ = β₀ + β₁x₁ + β₂x₂ + ... + βₚxₚ
추가로 다루어야 할 개념:
- 다중공선성 (Multicollinearity) — VIF로 진단
- 변수 선택법 — Forward / Backward / Stepwise
- 조정 R² (Adjusted R²) — 변수 개수에 따른 보정
- 가정 검정 — 정규성, 등분산성, 독립성
참고: sklearn 공식 문서 https://scikit-learn.org/stable/modules/linear_model.html
Comments